PM-WaiGaya
コンサルタントのトーク動画

前回のブログで、パッケージ導入の際は企業の特徴をきちんと分析&可視化した上で実装に臨むべきとお話した。今回はこの手段として、モデルがどう機能するかお話したい。
パッケージ導入は汎用モデルが既に製品化されている前提で始まる。このモデルを、パッケージが本来保有している価値を損なうことなく、できるだけ安価なコストで自社に適合させたい。ここで大事なのは原型の価値を失わないことである。パッケージの価値(自動化による省力化、優れたUIによる操作性、部品化による保守性など)はシステム化によるビジネス効果そのものであり、それが失われてはROIが得られないことになる。
さて、この原型を失わずにアドオン、カスタマイズするためのモデリング手法を説明する。まずはデータモデルについてお話する。最初にマスタに着目し自社とパッケージのER図を比較。自社とパッケージの対比で、対応する概念エンティティが存在しない場合はテーブル・アドオン。存在する場合は、論理モデルの状況により対応方法が分かれる。KEYが同一で属性が不足している場合は属性の追加となるが、不足したデータ群の性質からパッケージのエンティティのサブタイプとして別テーブル化することもある。またKEYが異なる場合は、両者が汎化・特化の関係にあることが多く、スキーマの変換が必要となる。(図1参照)
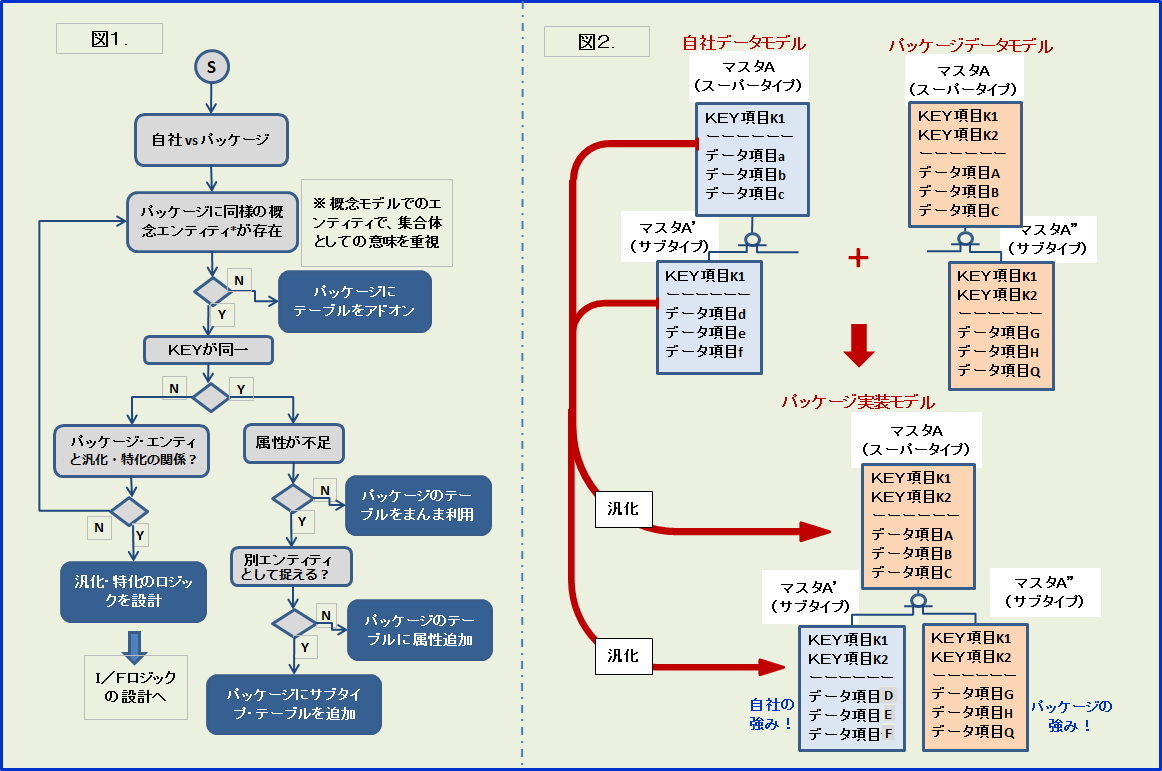
ここで注目したいのが汎化・特化関係である。汎化・特化はスキーマの自動変換ロジック(縦持ち横持ち変換)が成り立つ。安易に別テーブルを新設せず、“自社のマスタを自動変換しパッケージに流し込む”インターフェースを作成すべきである。安易なテーブル・アドオンはシステムのサイロ化を助長するので避けなければならない。一方で、自社モデルにないパッケージ固有のデータ項目群はサブタイプテーブルとなり、自社モデルから流し込まれたスーパタイプとペアで利用される。“パッケージのサブタイプはパッケージの良さ、自社のサブタイプは自社の強み”を表わす。これらを可視化することが、パッケージの価値を失わずに自社の強みを実装することに繋がる。プロジェクトに先立つ現状のデータモデリングにて、予めスーパタイプ、サブタイプ表記をしておけば、上記の手順を適用し易い。(図2参照)
次にトランザクションモデルの適合は、マスターモデルの適合を前提に設計されることになる。さらに、これらのデータモデルに続いて、今度はプロセスモデルの差異分析を行うことになる。ここでは、これらの手順の説明は省略する。
いずれにしてもプロセスよりデータモデル(中でもトランザクションよりマスタ)が優先で、FIT&GAPにおける最重要プロセスとなる。パッケージ導入時のFIT&GAPでは、実現機能の表面的比較だけでなく、内部のデータモデルの本質的比較をする事が成功要因である。また、物理モデルを非公開のパッケージでも、ユーザ企業として概念、論理モデルの公開を求めることは至極当然である。なぜならビジネス・システムは未だコモディティ製品の領域にはないのだから。
