PM-WaiGaya
コンサルタントのトーク動画

前回のブログではHUBアーキテクチャのメリットと基本的メカニズムについてお話したが、今回はさらにHUBアーキテクチャの進化形についてお話したい。以下の図1は前回ブログに掲載したものと基本構造は同様であるが、HUBの左肩部分にREPOSITORY(リポジトリー)の存在を加えたものになっている。今回はこの部分について言及してみたい。(バックナンバーに一般的な[REPOSITORY]の意義が書かれているので参照されたい)
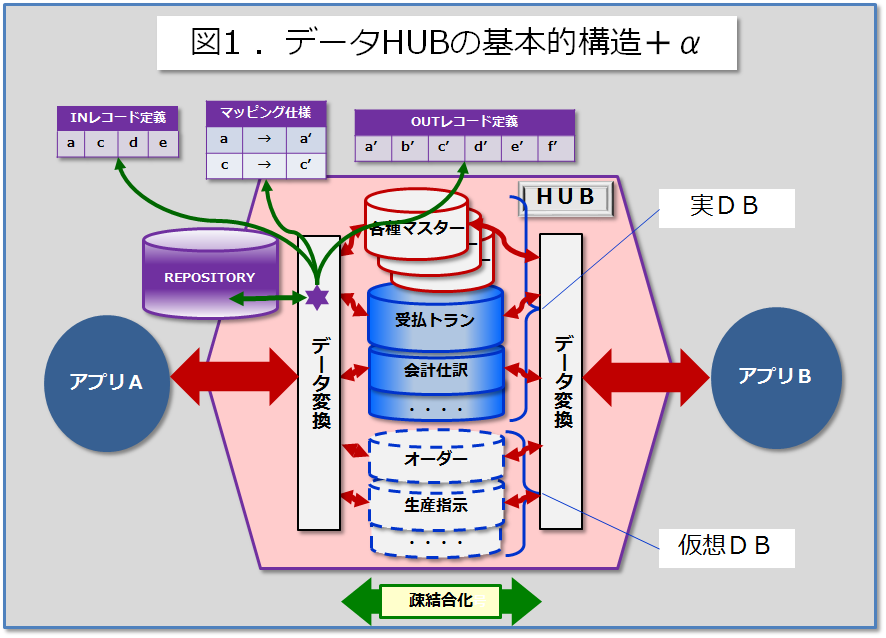 前回ブログでは、HUBのメリットがI/Fのデータや処理を可能な限り汎化し1箇所に束ねることで、エンタープライズ全体の類似したコード量を減らしメンテナビリティを高めることであることを説明した。では、アプリからHUBを介して集配信されるデータやレコードの汎用フォーマット定義や、データ変換処理のマッピング定義はHUB上に生成されるI/F毎に毎回ソースコードをCOPY&PASTEして書いて行くのであろうか。答えは否である。そこではデータHUBにおいて共通DBのインスタンスが再利用されるのと同様に、レコードやマッピング処理の定義をREPOSITORYに格納&再利用することで、HUB内のデータ処理コード量をさらに極小化し品質向上を狙いたい。
前回ブログでは、HUBのメリットがI/Fのデータや処理を可能な限り汎化し1箇所に束ねることで、エンタープライズ全体の類似したコード量を減らしメンテナビリティを高めることであることを説明した。では、アプリからHUBを介して集配信されるデータやレコードの汎用フォーマット定義や、データ変換処理のマッピング定義はHUB上に生成されるI/F毎に毎回ソースコードをCOPY&PASTEして書いて行くのであろうか。答えは否である。そこではデータHUBにおいて共通DBのインスタンスが再利用されるのと同様に、レコードやマッピング処理の定義をREPOSITORYに格納&再利用することで、HUB内のデータ処理コード量をさらに極小化し品質向上を狙いたい。
このようにHUBは単に複雑なデータ連携を束ねる交差点整理としての役割から、DB蓄積機能を用いての共有データ(マスタや取引明細など)の再利用、さらにはREPOSITORY内の共通定義を用いたI/Fシステムの品質管理へと進化をしている。まさに、ネットワーク機器のHUBでいうところの“バカハブ”ではなく“インテリジェントハブ”としての存在になっていると言えよう。これでお解かりいただけただろうか。このインテリジェントHUBは、単にアプリAからアプリBにデータを届ける“ファイル転送ツール”とは明らかに異なることが。目指すところは、エンタープライズシステムという情報製造工場における“原料と製法の品質保証”や“製造工程のコストダウン”の実現なのである。
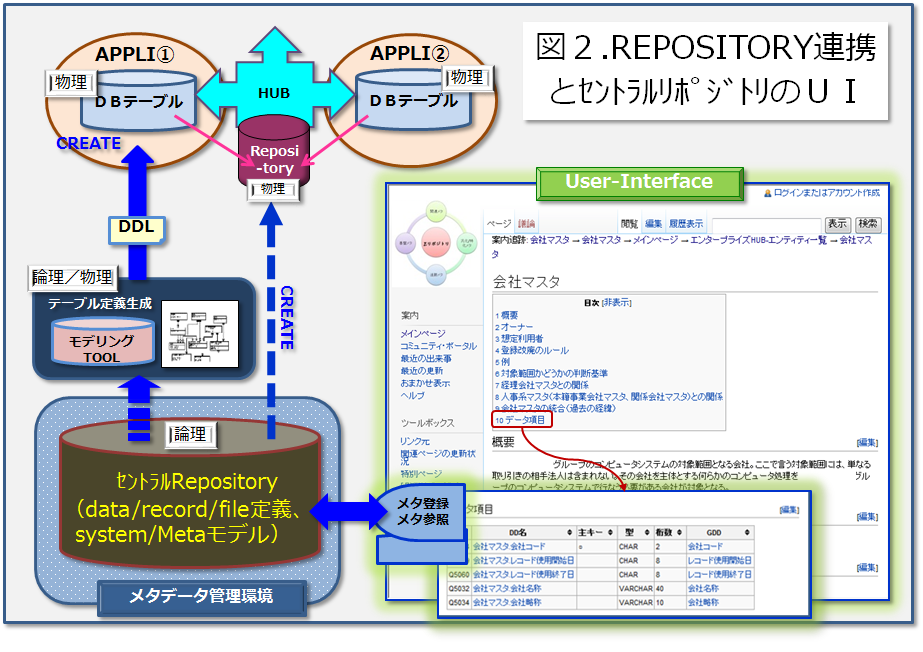 さて、このREPOSITORY上の定義体をさらに遡ると、最上流には当該企業のビジネスルールに基づくデータの意味や形式(型、桁)、それに基づくレコード、ファイルの定義といった基本的なシステム部品としてのメタデータ定義に辿り着く。図2に各レベル別に存在するREPOSITORYの連携を図式化してみた。この図は企業におけるあるべきメタデータ管理環境を示しており、水源には、どんなシステム実装環境の色にも染まっていないビジネスモデルに準拠したピュアな“セントラルREPOSITORY”が存在する。ここで一元管理されたメタデータをもとに、1つはモデリングTOOL内の(ローカル)REPOSITORYを経由して実DBテーブルの作成へと繋がる。もう1つは上述のHUB上の(ローカル)REPOSITORYのメタデータ定義へと繋がる。さらに、図2の右側にメタデータ定義コンテンツの一例を画面のUser-Interfaceとともに掲載した。この例は会社マスターの定義例であるが、エンドユーザでも容易に読める自然言語での記載となっている。なお、メタデータ定義は実装とは無縁なので、その格納先は実装とN:1の関係にあるセントラルREPOSITORY以外には考えられないことになる。
さて、このREPOSITORY上の定義体をさらに遡ると、最上流には当該企業のビジネスルールに基づくデータの意味や形式(型、桁)、それに基づくレコード、ファイルの定義といった基本的なシステム部品としてのメタデータ定義に辿り着く。図2に各レベル別に存在するREPOSITORYの連携を図式化してみた。この図は企業におけるあるべきメタデータ管理環境を示しており、水源には、どんなシステム実装環境の色にも染まっていないビジネスモデルに準拠したピュアな“セントラルREPOSITORY”が存在する。ここで一元管理されたメタデータをもとに、1つはモデリングTOOL内の(ローカル)REPOSITORYを経由して実DBテーブルの作成へと繋がる。もう1つは上述のHUB上の(ローカル)REPOSITORYのメタデータ定義へと繋がる。さらに、図2の右側にメタデータ定義コンテンツの一例を画面のUser-Interfaceとともに掲載した。この例は会社マスターの定義例であるが、エンドユーザでも容易に読める自然言語での記載となっている。なお、メタデータ定義は実装とは無縁なので、その格納先は実装とN:1の関係にあるセントラルREPOSITORY以外には考えられないことになる。
長持ちするITアーキテクチャにとって大切なことは、ここでも論理/物理の切り分けである。具体的アプリケーション、さらには具体的HUB製品にも依存しない、徹底的に実装非依存な”セントラルREPOSITORY”が企業にとって最も価値ある資産ということになる。そしてこのREPOSITORYのコンテンツは自社のレジェンド達の知識を集結して地道に作るしかない。決してお金で買う事はできないものである。
