PM-WaiGaya
コンサルタントのトーク動画

今回は、データやプロセスに関する情報処理部品の共有化について書いてみたい。「何を今さら!」と思われる読者の方も多いのではないかと思われるが、私の知る限り、規模の大小はともかく実装環境において共通部品の一元管理・共有化が正しく行われている会社は極めて少ないのが事実だからである。そしてこのことはシステムの生産性や保守性を妨げ、行き着くところITコストに多大な影響を与えている。共通部品には、データやプロセスの共通部品が存在するが、前者には複数システム間で共有すべきマスタやトランザクションデータが、後者には類似性の高いプロセスを汎化し複数システム内で再利用を可能にするコンポーネント等が該当する。そしてプラットフォーム非依存なデータ共有に比べて、実装環境の依存度の高いプロセス共有の方がやや難易度が高い。本ブログではこれらの部品の共有化が出来ていない典型例を挙げその真因を探るとともに、あるべき姿に向けたアプローチについて述べてみたい。
そもそも、部品化アプローチを妨げる元凶は、不幸にもソフトウエアの最もパワフルな機能である“COPY(複写)”に起因する。ひとたびCOPY&PASTEされたコードは独り歩きを始め、もはや一元管理は不可能となる。アプリケーションの緊急保守で共通データやコンポーネントを利用せずに“それ”をやってしまった事を懺悔する等は、まだ可愛いものである。
企業システムにおける大規模なCOPY&PASTEの最たるものが、いわゆる”横展開”のアプローチである。通常、横展開はビジネスモデルの類似性の高い複数の事業拠点や、グループ企業への順次展開で用いられる。この取り組みは、2つ目、3つ目の類似システムの早期立上げだけを考え、将来のメンテナビリティには目を瞑る、部品化の観点からみると最も罪深きものと言える。
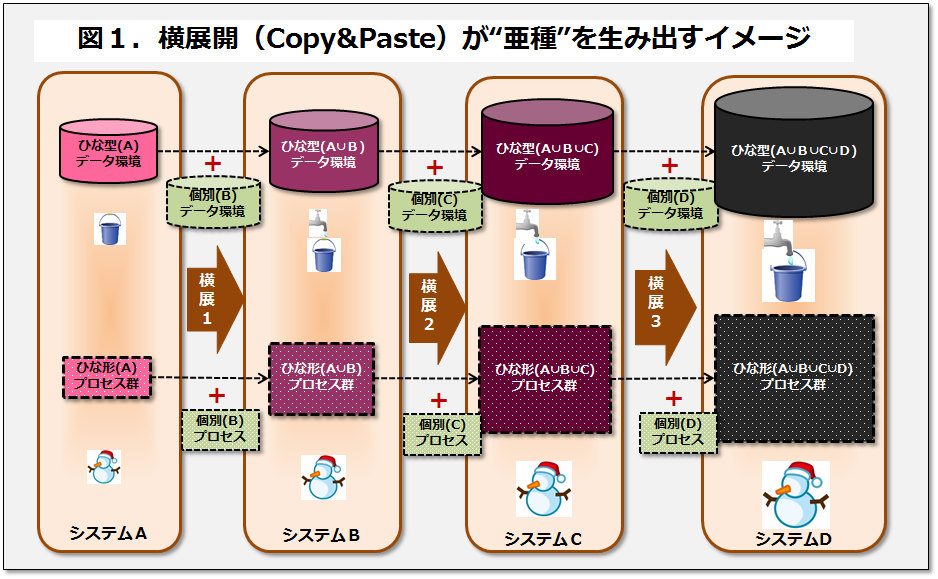
図1に「横展開が亜種*を生み出すイメージ」を図示してみた。データ環境においてもプロセス群においても、丸ごとシステムをCOPYした後で差分の追加修正が施される格好である。図の上部を→に沿って見て行くと、横展開の回を重ねるうちに、複数システムの和集合となったデータ環境(テーブル定義の属性、インスタンス、システム内テーブルの種類など)は最初の”ひな形“から順に変異した亜種*となって行くことが見て取れる。あたかも、単純COPYではなく”展開の都度、水増しされるバケツリレー“の如き様相である。図の下部を→に沿ってみると、ひな形となるAシステムのプロセス群が、横展開を重ねる毎に、複数システムのプロセス要素を盛り込んだ和集合として、徐々に肥大化して行くことが見て取れる。それは、あたかも、横展開の過程で、転がる雪ダルマが徐々に大きくなる様相だ。データ環境、プロセス群いずれも、複数システム間での共通/個別の区別が明確でないので、展開後の”全部保守“は困難を極める。余談であるが、私の経験上、横展開は2つ迄がいいところである。
では、なぜこのような結末となったのであろうか?その真因は何だったのだろうか?確かに、10数年前までは「ネットワーク環境もサーバー機を始めとするハードウエア環境も能力が低くハードウエアを現地に分散設置せざるを得ないというアーキテクチャが必然であった。しかし2009年頃を境にネットワークもハードウエアも既に相当の進化を遂げ、仮想化技術とともにクラウドサービスも立ち上がり、ソフトウエア環境はシングルインスタンスを追求できるレベルに近づきつつあった。にも拘らずなぜ安易な横展開に向かったのだろうか。。。横展開で最も潤うのが誰か?を考えれば直接の原因は明らかである。しかし、ITベンダーがコードの量やハードウエアの数によって収益が上がるビジネスモデルである事を知っていながら、開発のみならず設計までをベンダーに丸投げしたユーザ企業側にも責任があるのだ。
さて、上記のような過ちを繰り返さない為に、ユーザ企業はどのようなアプローチを採れば良いのだろうか。設計時のベンダー丸投げ体制は直ちに正すとして、何を最初に手掛ければよいのだろうか?それは全社(全グループ)を対象としたアーキテクチャを描く事である。描き方はコンサルやベンダーの指導に頼っても良いが、あくまでも自社で描画することが大事である。
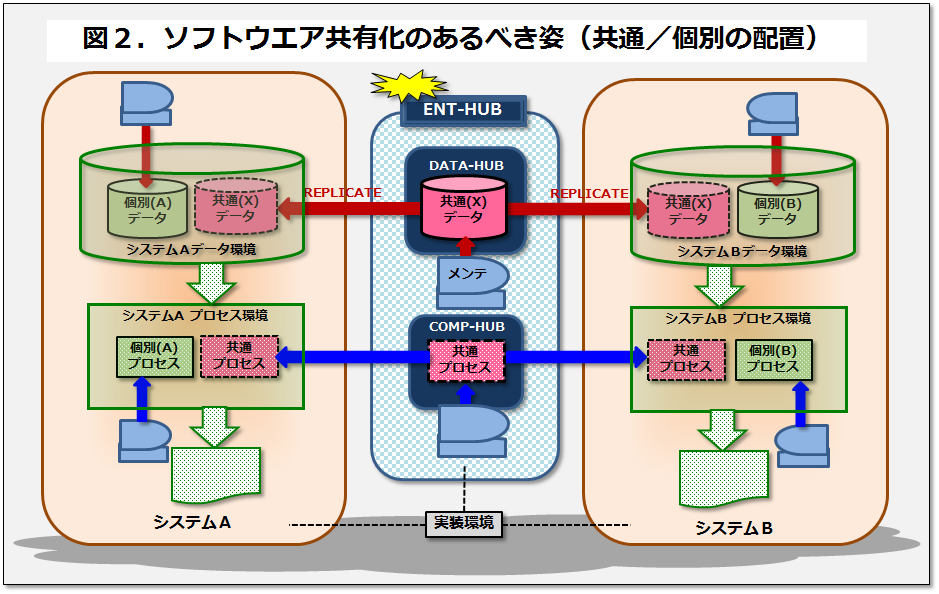
図2に「ソフトウエア共有化のあるべき姿」のイメージを掲載した。実際は自社のビジネスに即した具体的なデータ名、プロセス名、システム名が入ったものを描き、データ連携やアクセス方式についても描く必要がある。この図の示す通り、ソフトウエア・アーキテクチャ設計の勘所は「共通のものは一元化し共有する事」である。言い換えればデータもプロセスも極力重複を排除するという事に尽きる。さらに、今後の疎結合アーキテクチャを意識すれば、「非機能要件を満たす為に、リアルタイム性を問わないデータはRead-Onlyのレプリカを許容する」という文面を付け加えておく。なお、図上ではDA(Data Architecture)とAA(Application Architecture)について記載したが、BA(Business Architecture)おける組織間の重複機能の排除や、TA(Technical Architecture)におけるバックアップ機能以外の重複排除も同様である。
いかがであろうか。アーキテクチャ設計はあくまでも図式化であり実際のソフトウエア制作まではしなくて良い。ブログのバックナンバーに度々記載しているが、”Think big, start small”である。採るべきアーキテクチャが決まっていれば、システム構築はベンダーに任せられる部分も多くなる。共通/個別の識別が決まっていれば、順に訪れるシステム開発において、少なくとも個別部分はベンダーに任せて良いことになる。システム開発において、自社の工数を最小化しながらも勘所を外さない為には、メリハリが肝心である。
※亜種・・・生物分類学上の単位の1つ。種の下にランクされる区分。種とするほどに違わないが、微妙に異なる特徴を持つ。
