PM-WaiGaya
コンサルタントのトーク動画

今回のブログは“リポジトリーを作ってみよう!“シリーズの最終回。前回から持ち越したプロセス部品の定義を加えて、企業システムのメタデータモデルをひととおり完成させてみたい。そして、このデータモデルをベースに、リポジトリーの主目的である情報資源管理の為の幾つかのユーザVIEWを導いてみたい。ちなみに、これらのVIEWによってシステムを可視化する事が、ブラックボックス化したシステムを抱える現代の大企業が真っ先にやらなければならない事である。リポジトリーの副次的な目的であるプログラムの自動生成はひとまず研究者に任せることとしたい。
まずは、企業システム・リポジトリーの完成に向けて、前回のモデルにプロセス部品を追加してみたい。図1「エンタープライズ・メタデータモデル(最終版)」の上部を見ていただきたい。図中(右側)に新たに追加したプロセス部品として3つのエンティティをピンク色の背景色で記載した。簡潔に説明すると、システム定義エンティティについては、文字通り“システム”についての記述を格納し、生産管理、販売管理、物流、会計、営業支援といった企業システムにおける最も大きな業務システム分類がこれに相当する。サブシステム定義は、上記のシステム定義を機能分割したもので、例えば生産管理システムにおける日程計画サブシステム、製造実績計上サブシステムや、販売管理システムにおける受発注入力サブシステム、入出荷サブシステム等がこれに相当する。
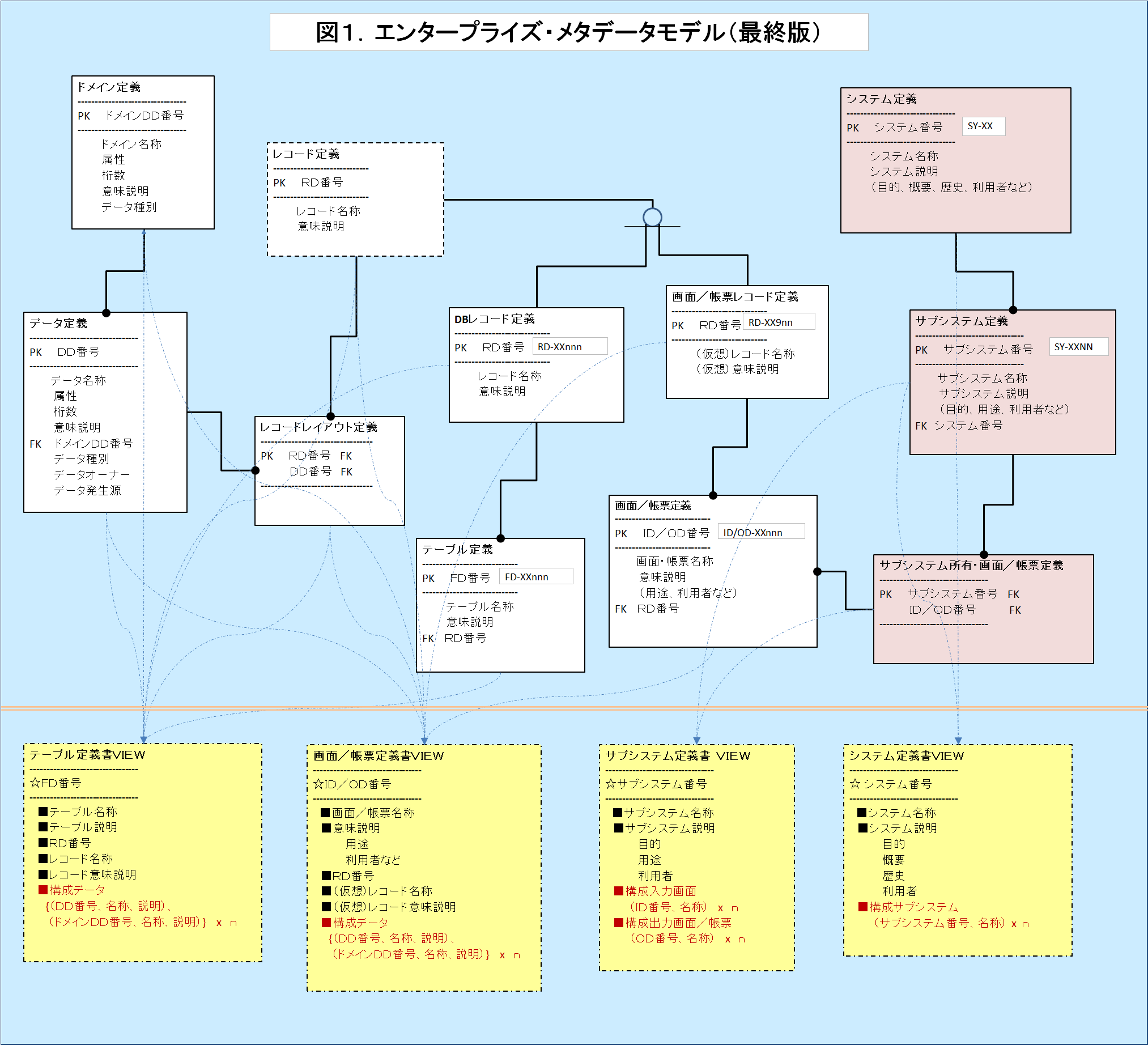 システム定義エンティティのP-KEYは、SY-XX(SY:SYSTEMの略、XX:システム番号)で表記。XXは、生産管理:A1、販売管理:B1、物流:C1という具合に英数2桁を組合せると良い。サブシステム定義エンティティのP-KEYは、SS-XXNN(SS:SUB-SYSTEMの略、XXNN:サブシステム番号)で表記。XXNNは、日程計画:A101、製造実績計上:A102という具合になる。そして、サブシステム定義内のシステム番号(F-KEY)で、システム定義とN:1で関係付けられている。
システム定義エンティティのP-KEYは、SY-XX(SY:SYSTEMの略、XX:システム番号)で表記。XXは、生産管理:A1、販売管理:B1、物流:C1という具合に英数2桁を組合せると良い。サブシステム定義エンティティのP-KEYは、SS-XXNN(SS:SUB-SYSTEMの略、XXNN:サブシステム番号)で表記。XXNNは、日程計画:A101、製造実績計上:A102という具合になる。そして、サブシステム定義内のシステム番号(F-KEY)で、システム定義とN:1で関係付けられている。
話は少しそれるが、この連載シリーズで度々登場する“P-KEY”の番号表記が、やけに煩わしいと思われる読者の方も多いのではなかろうか。私も初めて情報システム部門に配属された時は、この付番作業が何とも無機質で堅苦しい物に思えたものであるが、多くのシステムが乱立する今日ではこの番号なくして識別する事は不可能に近い。にもかかわらず、大企業でも未だに名称や愛称だけで運営されている会社が驚くほど多い。分業が進み、一担当者から見れば類似名の識別はさしたる問題とならないのか、話題の文脈によって暗黙知で識別できるレジェンド社員が優秀なのか分からないが、システム横断で物事を考える“EA”にはユニークIDは必須である。システム部品をユニークに識別するIDがなくてもやって行ける事と、我が国が今までマイナンバー制度がなくてもやって来れた事は、共通の文化的背景によるのだろうか。
話をメタデータモデルに戻そう。今回は前回のメタモデルにシステム、サブシステムの定義を追加したが、プロセス部品にはもっと細かい“プログラム”の存在や、さらに分解した“コンポーネント部品”といったものがある。しかしシリーズ(その1)でも書いた通り、プログラム言語の多様化を招いた今日、プロセス部品の捉え方には細部になるほど自由度が多く、部品点数が極めて多い事から、リポジトリーの永続的メンテナンスを考えると、サブシステム程度迄が現実的であろう。実際、前職ではプログラム定義のメンテナンスでさえ5年で破綻している。
さて、完成したメタデータモデルは活用されてなんぼのものである。図1の下段に、左からレコード定義書、画面/帳票定義書、サブシステム定義書、システム定義書といった4つのユーザVIEWを黄色の背景色で掲載した。これらはいずれも、正規化されたメタデータモデルから1:1又は1:Nの結合により導かれる。図上では、青色一点鎖線で参照するテーブルと紐づけている。これらのVIEWは、いずれも下位コンポーネントを繰り返し項目として横持ちに特化させており、一目で構成要素が分かるようになっている(図上で赤字で表示)。システム定義書、サブシステム定義書では、当該システム・サブシステムの処理(プロセス)概要及びインプット/アウトプット、すなわちI-P-Oの概要記述を見て取ることができるし、画面/帳票定義書、テーブル定義書では、その構成要素である各データ、ドメインの説明記述を見て取ることができる。
先日のJUAS統計で、売上高100億~1,000億円の企業ではブラックボックス化したシステムが全体の29.2%あるといった記事を見かけた。1000億~1兆、1兆以上といった企業においてその%が減っていたのはやや疑問だが、システムが大規模になればなる程、どうすれば効率的にシステムを説明できるかを考える必要がある。ムダのない説明の為に、システム部品(メタデータ)の正規化されたモデルが必要となる理由がここにある。従って、様々な脚色を施した説明資料以前に、このメタデータモデルに基づくリポジトリー作成がシステムの可視化の事始めとなる。大規模システムの見える化には、”システムを説明するシステム”が必要なのである。
