PM-WaiGaya
コンサルタントのトーク動画
DX(デジタルトランスフォーメーション)推進コンサルティング 株式会社アイ・ティ・イノベーション

今回のブログはリポジトリの作成がテーマ。本ブログシリーズでもシステムの仕様を格納するデータベースとして、その重要性に度々触れてきた。(バックナンバー2014.5.7「REPOSITORY」参照)。とりわけデータの仕様であるメタデータの格納に関しては永続的な再利用が可能である旨を説いてきたつもりである。今回はそのメタデータの入れ物(=リポジトリ)を作ってみたい。
ここで途端に「そんな難しそうな事、よほどのマニアでもなければユーザ企業には関係ないのでは?」と思われる読者の方も多いのではなかろうか。心配ご無用、ここではプログラムの自動生成を目的とするような本格的なRepositoryではなく、情報資源管理のみを目的とした簡単なメタデータの格納庫のデザインに留めたい(と言っても小さなデータベースシステムではあるが)。
「図1. サンプル・メタデータモデル」を見ていただきたい。図の左側は、レコード(エンティティクラス)⇒データ⇒ドメインという階層構造のメタデータを、どのようにメタデータモデル化するかを表わしている。そしてさらに分かり易くする為に、図の右側に各部門の従業員台帳と給与明細といったアプリ・データモデルを、メタデータのIDを添えて掲載した。そして図の下段には、レコード定義、レコードレイアウト定義・データ定義、ドメイン定義などをサンプル・アプリのケースでのインスタンス(実際の値)を例示した。(レコードレイアウト定義、デ-タ定義は”部門マスタ”のみ掲載し、他は省略)
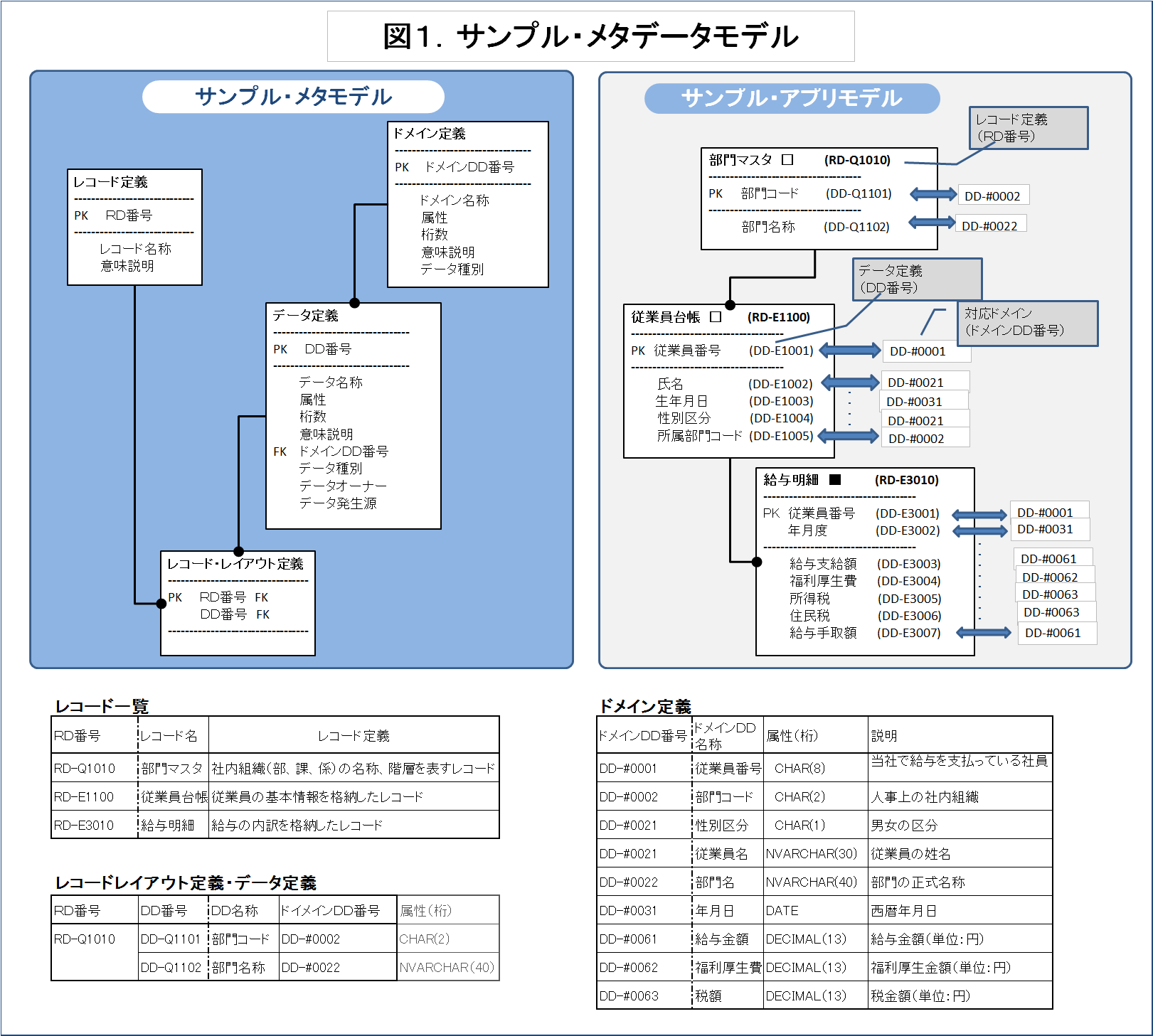
作成順としては、まず最初はレコード(エンティティクラス)定義を格納する入れ物を作成する。レコードをユニークに識別する為に”RD番号”(RD-XXnnn)というプライマリKEYを創設する。メタデータモデルにおいてもアプリモデル同様に、レコード1件毎を識別するID(KEY)を付与する必要がある。最低限ユニークであれば良いが、発番のし易さと見た目の分かり易さから [システム番号XX+連番nnn] にしておく等の工夫が必要である(図1の例でXXは、E1:人事基本、E3:給与計算、Q1基本マスタ管理)。また、先頭の“RD-“はRecord Description(レコード定義)の略で、”DD-”Data Description (データ定義)と同様に、一目で何の定義かが分かるように付与している。そして属性には、レコード名称やレコードの意味説明を格納する。さらには、レコードの構成要素としてのデータ定義も属性に入れたいところだが、保有データ個数が不定なので、ここは第一正規形の”繰り返し項目 の排除”に則り、”RD番号 and DD番号” (RD-XXnnn and DD-XXnnn)をプライマリKEYに持った”レコードレイアウト”と命名された別エンティティを切り出す事にする(このエンティティクラスの属性の説明は省略)。
次に、データ定義を格納する入れ物を作る。プライマリKEYは先程のDD番号(DD-XXnnn)とし、属性にはデータの名称、意味説明、データ型、桁、データ種別(コード、区分、数量、日付)、データオーナー、データ発生源そして”対応ドメイン”などが格納される。(これら属性定義の書き方は、バックナンバー2014.5.24「データ辞書の整理法」に詳しく記載)。ここで言うドメインとは、従属するレコード(文脈)に依存しない企業システムの基本となるメタデータを言う。データの形式(型、桁)、原始的意味はここで決定付けられる。例えば、従業員マスタのKEYとしての従業員コードも、給与明細上のそれも、”従業員コード”というドメインの形式や原始的意味が継承されることになる。そういった意味では、データ定義を格納する前に、ドメイン定義を作成しておく事が好ましい。但しある程度、個別のデータ定義を進めてみないと共通項としてのドメインが見出せないこともあるので、最初のうちはデータ定義とドメイン定義を並行して進め、ある地点からドメインを先に整理した上で、個別のデータ定義にまわることをお勧めする。ドメイン定義のプライマリKEYは通常のデータ定義と区別する為にDD-“#“nnnnとする。属性にはデータ定義同様に、デメインデータ名称、意味説明、データ型、桁、データ種別(コード、区分、数量、日付)が格納される。そして、あえて言うならば、ドメインを継承した個別データ定義の側では、これらの属性定義を省略しても良いという事になる。
どうであろうか、ここまででドメイン→データ→レコード(エンティティクラス)と繋がるメタデータのトレーサビリティが確立する。さらにリポジトリをシステム保守の現場で用いるためにはレコードを保有する物理的なテーブル定義までは欲しいところである。また欲を言えば、ここでは扱っていないシステム⇒サブシステム⇒プログラムといったプロセス部品や、入出力画面やレポートと言ったI-O部品、そしてそれらのコンポーネント間の関係をリポジトリに格納できれば言う事はない。ここまで行けばリポジトリは完成の域に達する。でも先走ることはない。プロセス部品は捉え方に自由度も高く量も多いのでなかなか手強い。またエンジニア気質につられプログラムの自動生成が目的になり、本来の情報資源管理の意味が薄れてしまう恐れもある。まずはデータ部品からでよい。足元のできるところからはじめよう。Think big , start small が肝心だ。
