PM-WaiGaya
コンサルタントのトーク動画

メタデータのさらなる汎化
今回は再びデータ管理の原点に戻ってメタデータの効率的管理について述べてみたい。今年に入り本プログシリーズは、Episode-1さながらデータ管理の基礎に遡る話題を取り上げているが、近年活況を呈してきたレガシーシステム再構築において、そもそもの成り立ちを知らずに迷走する様を、見るに耐えかねての事と思っていただきたい。
”メタデータ”とはデータを抽象化したものである。従業員台帳の例で考えて見ると、表1のように整理される。氏名、生年月日、住所などはデータを見ただけで何の事か想像がつくが、従業員番号、所属部門コード、社員区分などは、データを見ただけでは何のことやら見当もつかない。
| 【 表1.従業員台帳の例 】 | ||
| 《データ》 | ⇔ | 《メタデータ》 |
| 3765022640 | ⇔ | 従業員番号 |
| 中山嘉之 | ⇔ | 氏名 |
| 1956.11.19 | ⇔ | 生年月日 |
| 神奈川県横浜市 | ⇔ | 住所 |
| 1 | ⇔ | 性別区分 |
| 312 | ⇔ | 所属部門コード |
メタデータを添えて初めて意味のある情報となるのだ(性別区分“1“や部門コード”312”はさらにマスタテーブルを参照して意味が分かる)。
このようにメタデータとはデータを補足説明するデータである。企業に存在するあらゆるデータを眺めてみると、このメタデータにも類似性を見て取ることができる。
図1の左側は従業員台帳と給与明細の簡易な人事系サンプルデータモデルで、図中の四角で囲われたエンティティの中身は“メタデータ“で記述されている。ちなみに、メタデータ名の右側に()書きで記された”DD-XnnNN”はメタデータを完全にユニークに識別するために番号付けしたものであり、エンティティ略番”Xnn“に紐付いて付番されている。
このデータモデル上に記載されたメタデータを、再び、所属エンティティを意識せずに、データの型、桁数、及び原始的な意味が同一のものを”ドメインデータ”として括り出してみる。図1右下にDD-#mmmmで付番されたドメイン定義が記載されており、左側のエンティティ定義内のメタデータと全て関連付けられている。エンティティ内メタデータと、ドメインデータの関係はN:1になり、その比率は全社規模のデータモデルの場合には10:1を上回る(当サンプルモデルは極めて狭い領域ゆえ2:1にも満たないが)。
< ↓図の文字が小さいので、図をクリックして拡大表示してご覧ください>
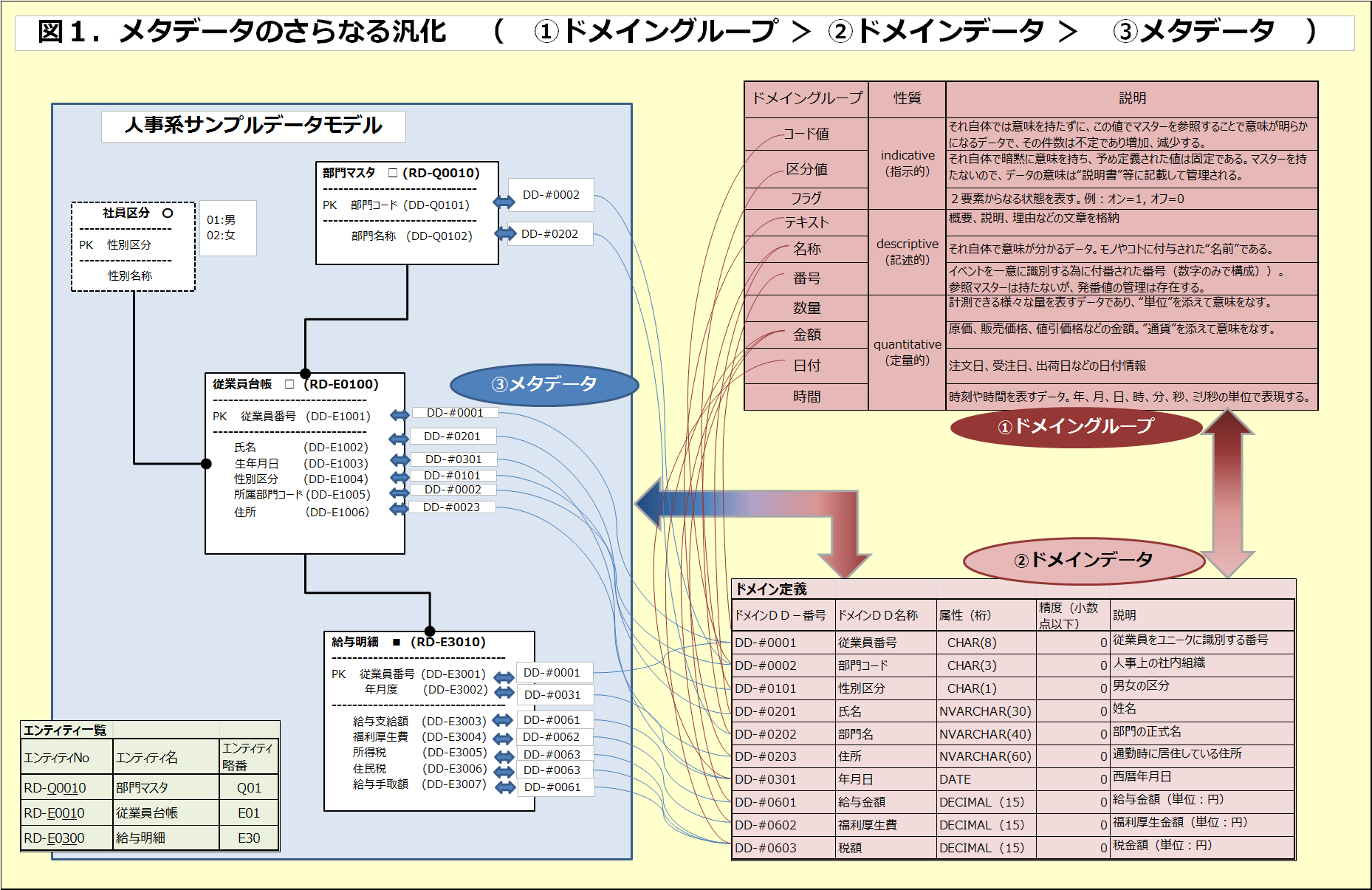
ここで少し補足説明をしておきたい。ドメインとしての括りの条件に、型、桁数などのシンタックスの同一性は分かりやすいいが、“原始的意味“の同一性となると難しい局面に遭遇する。その典型が数量や金額のドメインである。データ型、桁数は数量関連、金額関連ともに社内一律に決められていたりするので、残る意味の同一性による分類となるのだが、これがいささか決め手に欠く。このサンプルの例でも給与金額、福利厚生費、税額の3者のドメインを分けているが、グルーピングの基準が曖昧なので”金額“一本のドメインとしても間違いとは言い難い。ここは絶対的な解があるわけではないので、将来、モデル化領域が増え、様々なメタデータが増えた際に、グループが分割されていることで管理性が高まるかどうかの観点から分割するのが良い。
ここまでで、メタデータをドメインによって汎化することができたことになる。これでドメインからメタデータへ、データ型、桁数が継承され、設計品質が向上することは間違いないが、さらなるもう一段上位の汎化ができないかを考えてみる。図1の右上を見ていただきたい。ここには“ドメイングループ”なるものが記載されている。企業内システムに存在するデータが、そもそもどのように大きく分類できるかといった観点から、“コード値、区分値、名称、テキスト、フラグ、番号、数量、金額、日付、時間”の10種類に分類されている。これらのドメイングループではデータ型を統一することが出来、グループの初期値を継承することで、配下のドメインのデータ型のゆらぎをなくすことが出来る。
このように、データの特性は上位から順に継承されるが、初めてこのドメインツリーを作成する際は、ボトムアップ(汎化)とトップダウン(検証)を繰り返しながら進めて行くことになる。そして、ひとたび自社の確固たるドメインが出来上がってしまえば、新たな領域のシステムを追加する際には、既設ドメインをマッピングすることは極めて容易となる。
以上、今回はデータをどのように抽象的に捉えれば、企業システムのデータベース環境がきれいに整理されるかという観点でお話した。ポイントはドメイングループ⇔ドメイン⇔メタデータ⇔データの系譜をたどり、各々の汎化⇔特化の階層関係を理路整然と整理されていることである。そして、もう1つ付け加えるならば、階層定義されたモデルが裾広がりに美しくバランスが取れていることである。そして読者の方々はもうお気づきと思われるが、これらの定義体を格納するデータベースこそが、メタデータREPOSITORYである。お時間がある方はバックナンバー2016.5.11「リポジトリを作ってみよう!(その1)」を参照されたい。
