間違いだらけのAI導入 失敗から生まれる目からウロコのAI活用
~AIの使い方次第で、DXの妄想スパイラルから抜け出せる~

主 催:株式会社アイ・ティ・イノベーション
共 催:エスディーテック株式会社、Global Walkers株式会社、株式会社システム情報、東芝デジタルソリューションズ株式会社
セミナーレポート[2]
- セミナーレポート[1]
- セミナーレポート[2]
- セミナーレポート[3]
第2回AI / Analytics カンファレンス『間違いだらけのAI導入失敗から生まれる目からウロコのAI活用~AIの使い方次第で、DXの妄想スパイラルから抜け出せる~』
2021年8月27日(金)に、第2回AI / Analytics カンファレンス『間違いだらけのAI導入失敗から生まれる目からウロコのAI活用~AIの使い方次第で、DXの妄想スパイラルから抜け出せる~』をWEBセミナー形式で開催し、120名の方にご参加いただきました。本カンファレンスについて、3回に分けてご報告いたします。2回目は主催者、共催者の講演ダイジェストをお届けします。
セッション1
AIシステム導入の効果評価とは~継続的なビジネス価値を生み出すために~
株式会社アイ・ティ・イノベーション
高度先端技術部 コンサルティングマネージャー 藪 彰文
経済産業省の調査によると、日本の中小企業におけるAI導入率(導入が決定している未導入企業を含む)は3%未満です。AIに対する詳細な理解がないことが導入の障壁になっています。AIに対する理解を高めることができれば、AI導入の推進につながると考えられます。本セッションでは、AIシステム開発・運用で陥りやすい罠をご紹介し、その対策について解説します。また、AIシステムの評価と効果検証を行う際のポイントを考察します。さらに、AIを活用して業務自動化や業務プロセス改善を実現する仕組みをご紹介します
AIシステム開発・運用で陥りやすい罠と対策
- 「とにかくAIを導入さえすれば効率化できる」という思い込みで進めてしまうと、期待した効果が得られず、理想と現実のギャップに悩むことになります。目標・目的・KPIを明確にしておく必要があります。
- 目標とする精度が曖昧だと、目標精度に達したのに業務では使えないということになりかねません。感覚に頼らない目標精度の設定が重要です。
- 現場に抵抗感があると、AIシステムを導入してもらえないケースもあります。事前に、現場の意見を正しく取り込んで合意形成しておく必要があります。
- 高精度なモデルを追求しすぎると、実用化できなくなります。実用性のある目標精度を設定する必要があります。
- 導入後、AI任せになってしまうと、変化していくデータに追随できずに精度が低下します。再学習を含めた運用プランを立てておくことが重要です。
AIシステムの評価と効果検証におけるポイント
機械学習モデル開発のプロセスは大きく「学習」と「推論」に分けられます。学習パイプラインにおいては、再現率や適合率などの評価指標を用いて、学習させたモデルの性能を測定します。ビジネス上の課題を解決するためには、評価指標の特性を正しく理解し、適切な指標を選択する必要があります。推論パイプラインにおいてはモデルの精度劣化を検知し、モデル再学習により精度を向上させることが重要です。
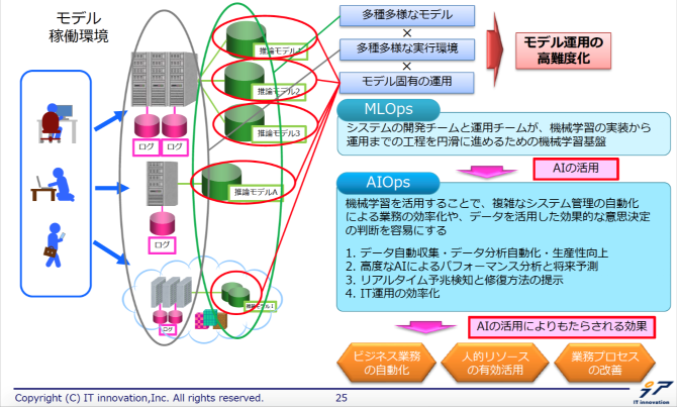
AIシステム開発の目的を達成するためのMLOpsとAIOps
MLOpsとは、機械学習モデルのライフサイクル全体を円滑に進めるための機械学習基盤を指します。AIOpsは、AIを活用してIT運用プロセスの自動化を図ることです。MLOpsとAIOpsを活用し、ビジネス業務の自動化、人的リソースの有効活用、業務プロセス改善といった目的を達成していくと、継続的なビジネス価値の創出につながると考えられます。

【藪 彰文 プロフィール】
1995年日本オラクル株式会社入社。Oracle DB導入のための機能評価や構築支援を行う技術SEとして従事し製造、金融、中央省庁を担当。
2002年株式会社東芝(現東芝デジタルソリューションズ株式会社)入社。大規模DB統合を伴う開発プロジェクトのDBチームリーダーのほか、中央省庁及び外郭団体の大規模Webシステム開発のプロジェクトマネージャーを務める。
2019年株式会社アイ・ティ・イノベーション入社。これまで培ったDB/ITスキルをベースにAIシステム導入に向けた高度先端技術を担う。
セッション2
AI-OCR開発の失敗から学ぶ「使えるAI」開発のポイント
グローバルウォーカーズ株式会社
取締役CTO 樋口 未来 氏
AI-OCRの開発には、手書き文字を読み取る難しさに加えて、日本語特有の難しさがあります。日本語の認識が難しい理由としては、文字種別が多いこと、横書きと縦書きがあること、単語数が多いことが挙げられます。本セッションでは、AI-OCR開発における失敗事例をご紹介しながら、失敗の原因と解決策を明らかにします。そこから、ビジネスで活用できるAI-OCR開発のポイントを解説します。
AI-OCR開発で起こりやすい失敗とは
実用化に至らなかったケースとして、物体検出のモデルを日本語認識に採用したら出力層が巨大になってしまったことがありました。使ったことのあるモデルや、有名なモデルを深く考えずに用いると失敗するという教訓を得ました。
また、教師データの不足や品質不備も失敗の原因となります。失敗した事例としては、横書きのみで学習したら縦書きを読み取れなかったケースや、教師データと異なるフォント・文字間隔で書かれた文書で精度が低下したケースがありました。表中の文字や、線と重なっている文字の誤認識や未認識も発生しました。こうした失敗を防ぐためには、実際に利用する環境を想定した教師データを準備する必要があります。また、誤認識・未認識は必ず発生するので、抽出して教師データに追加することが重要です。
ビジネスで活用できるAI-OCR開発のポイントとは
AI-OCRに対して適切なモデルを選択しましょう。一例としては、「文字列検出+文字認識+自然言語処理(必要な場合)」のモデルがあります。
高い精度を実現するためには、事前に文字のエリアを定義しておくなど、課題を簡略化すると効果的です。ただし、100%の精度を出すことは非常に難しいため、100%の精度でなくても成立する運用・システム設計が重要です。人間による確認と修正が必要になることも考慮しておきます。
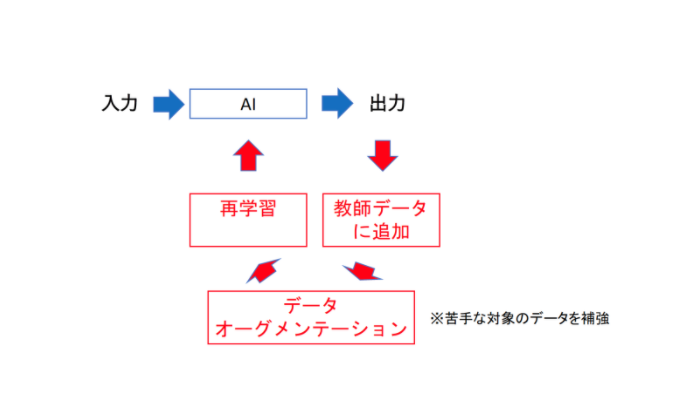
精度向上のためには、継続的に教師データを作成し、再学習を行います。元のデータを加工して件数を増やすデータオーグメンテーションを活用すると、効率的に教師データを拡張できます。
AI-OCRは需要が高く、巨大企業も注力している領域です。ビジネス化するためには、ターゲットとする事業や文書を絞り込むなどして、自社の強みとなるポイントを見つけていく必要があると考えています。

【樋口 未来 氏 プロフィール】
株式会社日立製作所 日立研究所、カーネギーメロン大学客員研究員にて車載ステレオカメラの研究開発、製品化などに従事。
その後、グローバルウォーカーズ株式会社を創業。専門は、コンピュータビジョン、Deep Learning。
セッション3
AI開発の裏側、お話します~失敗しないAIプロジェクトの進め方~
株式会社システム情報
取締役 ソリューション副本部長 足立 雅春 氏
AI導入プロジェクトで最終的に達成すべき「本来の目的」は、DXの実現です。
本セッションでは、DXの実現に必要なAIプロジェクトを正しく進めるために、アセスメントに有効なフレームワークやプロセスをご紹介します。また、DXを支えるデータ基盤について解説します。
AI導入プロジェクトを成功に導くアセスメント
AI導入プロジェクトを成功させるためには、適切なアセスメントが重要です。アセスメントには「プロジェクト計画」、「課題抽出」、「類似事例調査」、「KPI設計・評価」があります。それぞれに有効な手法をご紹介します。
「プロジェクト計画」には、デザイン思考・アジャイル開発・リーンスタートアップに関する基礎知識やフレームワークが有効です。「課題抽出」においては、デザイン思考・アジャイル開発・データ分析プロセスが有効です。「類似事例調査・比較」と「KPI設計・評価」には、データ分析プロセスが活用できます。
従来型のシステム開発で培われてきたのは、ウォーターフォールをベースにした演繹的なアプローチでした。それに加えて、AI導入プロジェクトではデザイン思考・アジャイル開発・リーンスタートアップ・データ分析プロセスのような帰納的アプローチも取り入れていく必要があります。
DXを支えるデータ分析基盤
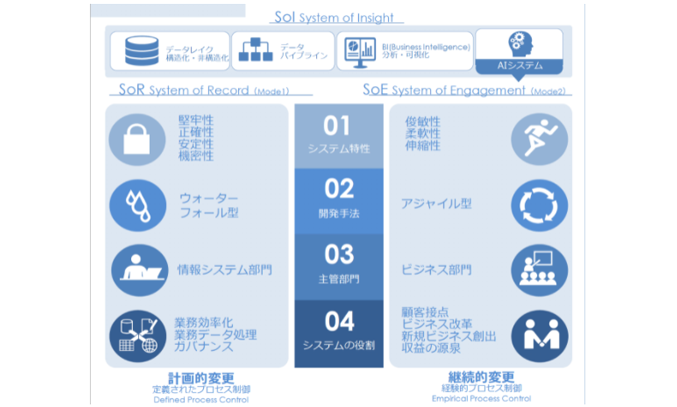
SoR(System of Record)とSoE(System of Engagement)が補完し合うデータ分析基盤が必要と考えています。それぞれで得られたデータを蓄積して統合することで、分析・可視化が可能になります。そこにAIシステムを組み込んで、顧客志向に合わせたフィードバックを繰り返していきます。
このように、データ分析基盤を活用して顧客の欲求や心理を理解しようとするシステムをSoI(System of Insight)と呼びます。SoIは、DX実現のために大きな役割を果たします。

【足立 雅春 氏 プロフィール】
独立系ソフトウェアベンダーを経て、2010年株式会社システム情報にSEとして入社。通信・金融をはじめ多数のシステム構築プロジェクトでリーダー/PMを歴任後、2014年にソリューション部門の立ち上げ時から統括部長としてAI・RPA・クラウドを中心に新規事業の責任者として従事。現在に至る。
セッション4
人間中心AI〜人を知るためのAI技術の活用とその難しさ
エスディーテック株式会社
取締役副社長 CTO 鈴木 啓高 氏
製品を利用するユーザーにとって大切なのは「利用時品質」です。本セッションでは、利用時品質を向上させるために有効な手段として「人間中心AI」をご紹介します。また、その開発の難しさや、失敗しないためのポイントを解説します。
利用時品質の向上に必要なのは「人を知る技術」
製品の品質を議論する際に、開発者とユーザーの視点が異なっていることがあります。開発者は「要件を満たしているか、異常はないか」という「機能品質」だけが品質であると考えてしまうことが多いです。一方でユーザーにとっての品質は、やりたかったことを効率良く、満足する形で実現できるかという「利用時品質」です。利用時品質を実現できなければ、機能品質が高くてもユーザーは満足しないでしょう。
利用時品質を向上させるためには、人間中心(ユーザー中心)で考えることが重要です。そのためには、ユーザーの行動を正しく理解する必要があります。しかし、人間の行動を理解することは容易ではありません。エスディーテックでは、「人を知る技術」にAIを取り入れて、ユーザーと製品の適切なインタラクションを進めることで、利用時品質の向上を目指しています。

人間中心AI開発で失敗しないためのポイント
「人を知るためのAI」を開発する上での難しさを知ることが重要です。データ取得の際は、データを収集すること自体が人間の行動に影響を与えるため、本当に必要なデータを取得しにくいという難しさがあります。さらに、ターゲットとしているユーザー層の分布に沿ったデータを収集するのが難しい場合もあります。
必要なデータを収集できたとしても、何を正解とするか定義して評価するのは困難です。性能評価の指針を定めきれない場合もあります。最終的な評価はユーザーにとっての「納得感」であることを視野に入れて、性能評価の設計を行う必要があります。
AI開発を継続的に行っていくと、本来の目的を見失いやすくなります。本当に実現したい価値は何か、最初の段階でユーザーを含めて議論し、定義してからプロジェクトを進めることが重要です。

【鈴木 啓高 氏 プロフィール】
株式会社エイチアイ取締役、HI Corporation America, Inc. CEO、株式会社U’eyes Design取締役を経て、2015年にエスディーテック株式会社の立ち上げに参画。現在は「世の中の全ての製品の利用時品質を向上する」ことを目指し、そのためのデザインと技術の研究開発に取り組んでいる。主に自動車の統合コックピットにおけるHMIを対象に、ヒトに対する理解とデザイン・技術を活用し、ヒトとクルマの様々な状況に応じたHMIをよりダイナミックに生成する仕組み作りが主なテーマ。
セッション5
データを事業に活かすために必要なデータ基盤とは
東芝デジタルソリューションズ株式会社
新規事業開発部 シニアエキスパート 望月 進一郎 氏
近年では、データを事業に活かす試みが盛んに行われています。しかし、データを収集し、AIを活用したシステムを稼働させても長続きしないことがあります。データを継続的に活用するためには、半自動化されたデータ基盤が必要です。
本セッションでは、データ基盤を構築する際のポイントを解説します。また、データ基盤を活用して業務を改善した事例をご紹介します。
データ基盤を構築する際に気を付けるべきこと
データ基盤には、「さまざまなデータを扱えること」、「高速に分析できること」、「データが増えても柔軟に拡張できること」など、多くの条件が求められます。データ基盤を構築する際は、長期的な使用を見越して、現在必要な仕様だけでなく将来の活用も検討しておく必要があります。
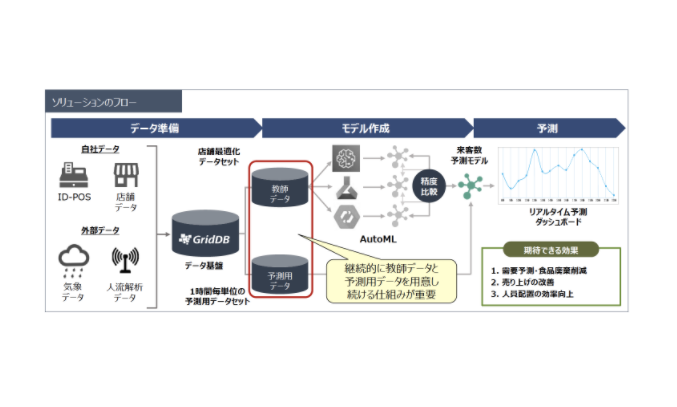
事例:食品廃棄物の発生を半減させるためのデータ基盤(GridDB)の活用例
大手食品スーパーマーケットの事例をご紹介します。この企業では、「各店舗で食品廃棄物の発生量を50%削減する」、「総菜市場の売り上げを20%アップさせる」という業務上の課題がありました。これらの課題解決のために、店舗単位の来客数を予測するシステム開発に着手しました。目標とした予測精度は90%以上です。
当初は複数店舗のデータを使って来客数を予測するモデルを作成しましたが、予測精度は目標に達しませんでした。原因として、特性の異なる店舗データを混ぜてしまったことや、モデル作成時点からの季節性・社会性の変化を反映していないことなどが考えられました。
そこで、自社データだけでなく、気象や人流などの外部データもデータ基盤に集約し、店舗ごとに必要なモデルを構築できるように改善しました。この改善により、予測精度90%以上を達成することができました。
これからのデータ基盤のあるべき姿
これまで、データ基盤の利用目的は主に「過去の分析」でしたが、これからは「将来の予測」が重要になります。そのため、リアルタイムでの分析・予測が可能なデータ基盤が主流になっていくと考えられます。
今後、企業が分析するデータはますます増加すると予想されています。ビッグデータに対応するためにはクラウドの活用が効率的ですが、セキュリティの観点からクラウドに保管できないデータも存在します。クラウドとオンプレミスのハイブリッド型を実現できるデータ基盤が求められるでしょう。

【望月 進一郎 氏 プロフィール】
株式会社東芝でミドルウェアの開発や商品企画に従事。現在は東芝デジタルソリューションズ株式会社でビッグデータ向けデータベースやデータ基盤の商品企画に従事。