1. はじめに
「NeurIPS」は毎年開催される国際会議で、「ICML」、「ICLR」、「CVPR」などと並ぶ、機械学習の分野で権威あるトップカンファレンスの一つである。今年、NeurIPSに投稿された合計9,122件の論文のうち、最終的に2,344件の論文が受理(受理率:26%)されている。
NeurIPS 2021は12/6~12/14(現地時間)に全てオンラインで開催された。
NeurIPS 2021の投稿論文に関する平均スコアは6.36であり、OralとSpotlightに相当する論文の平均スコアは約7ポイント以上であった。
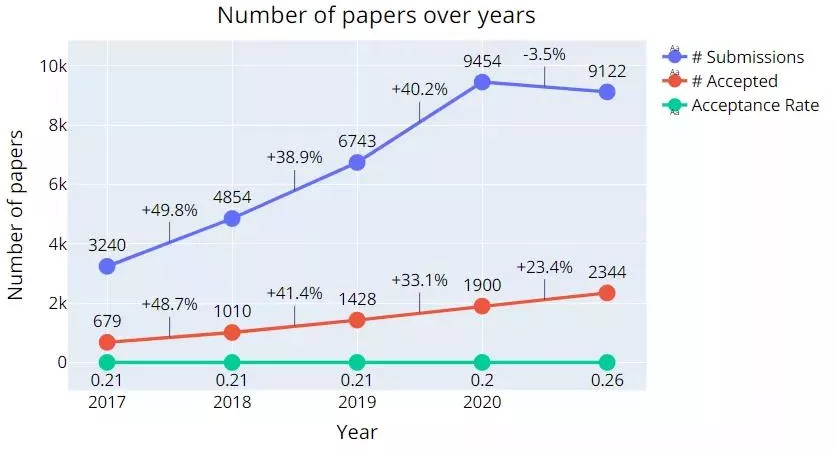 図1:NeurIPS2021での投稿数と受理数の比較 ※1
図1:NeurIPS2021での投稿数と受理数の比較 ※1
企業別のアクセプトされた論文数上位3社は、Google(177論文)、Microsoft(116論文)、DeepMind(81論文)となっていた。
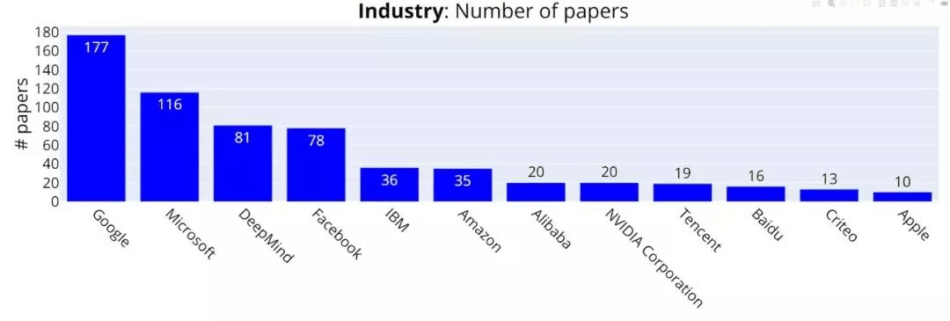 図2:NeurIPS 2021 企業別の承認論文数 ※1
図2:NeurIPS 2021 企業別の承認論文数 ※1
また、大学別のアクセプトされた論文数上位5校は、MIT(Massachusetts Institute of Technology)(142論文)、Stanford University(139論文)、CMU(Carnegie Mellon University)(117論文)、UCB(University of California, Berkeley)(116論文)、清華大学(90論文)となっていた。
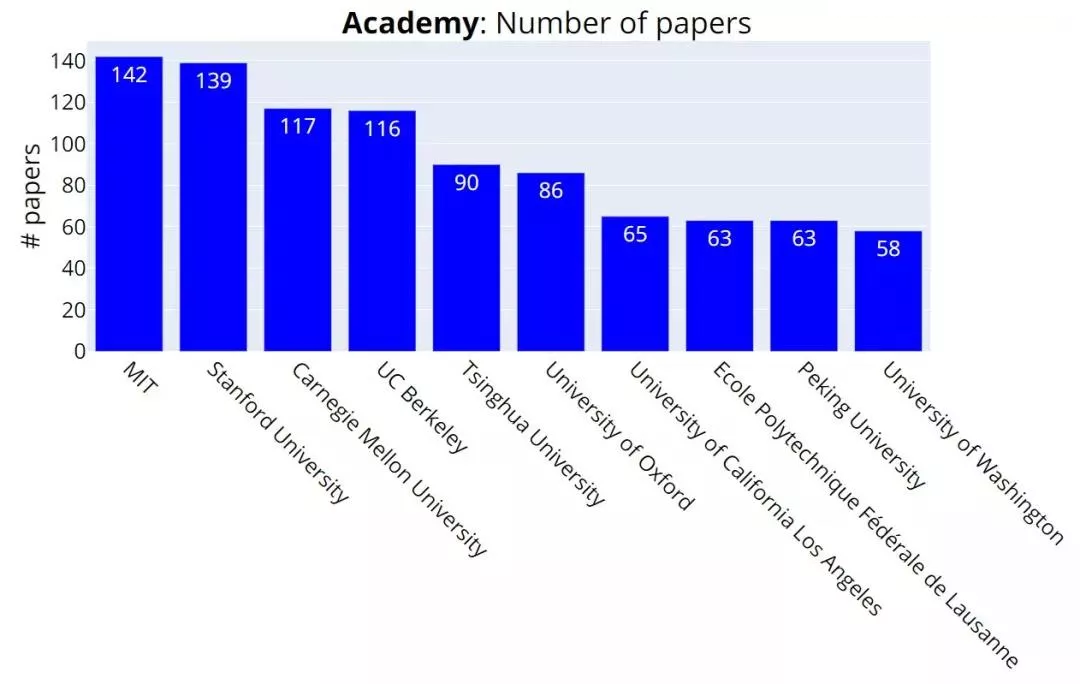 図3:NeurIPS 2021 企業別の承認論文数 ※1
図3:NeurIPS 2021 企業別の承認論文数 ※1
研究機関・企業ともに米国、中国が目立つ印象であった。そこで、国別でアクセプトされた論文数上位3カ国を見たところ、やはりアメリカ(1431論文)、中国(411論文)、イギリス(268論文)となり、米国・中国の論文数が多いことを実感できる(日本は12位)。
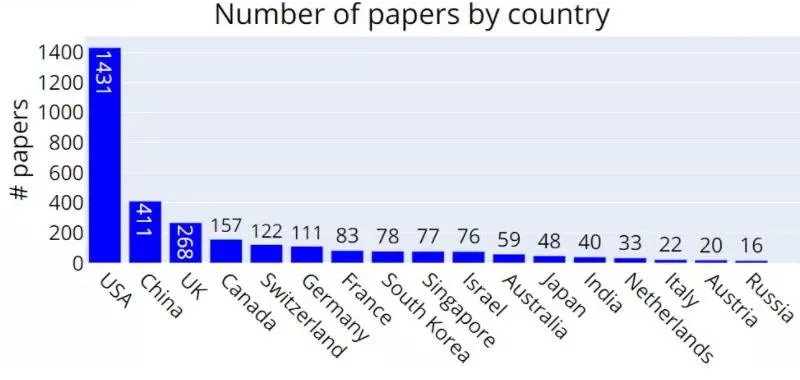 図4:NeurIPS 2021 国別の承認論文数 ※1
図4:NeurIPS 2021 国別の承認論文数 ※1
また、今年の参加形態であるが、全てリモートを通しての参加となっていた。リモート参加に関する特記事項として、NeurIPS2021のポスター発表では、「gather.town」(参考URL:https://www.gather.town/)というアバターシステムでポスター発表を行っていたことが挙げられる。「gather.town」でカメラとマイクを用いて、リアルと同様に討論出来るだけでなく、タイムゾーンが異なる国に居ながらも、出張費用を抑えて家から気軽に参加出来ることはメリットが非常に大きいと感じている。

図5:NeurIPS2021 ポスター発表の様子
2. NeurIPS 2021の投稿論文・Awardから見たAI技術トレンド
NeurIPS2021の投稿論文に取り上げられていたキーワードを分析すると、「reinforcement learning」が非常に多いことが分かる(図6参照)。
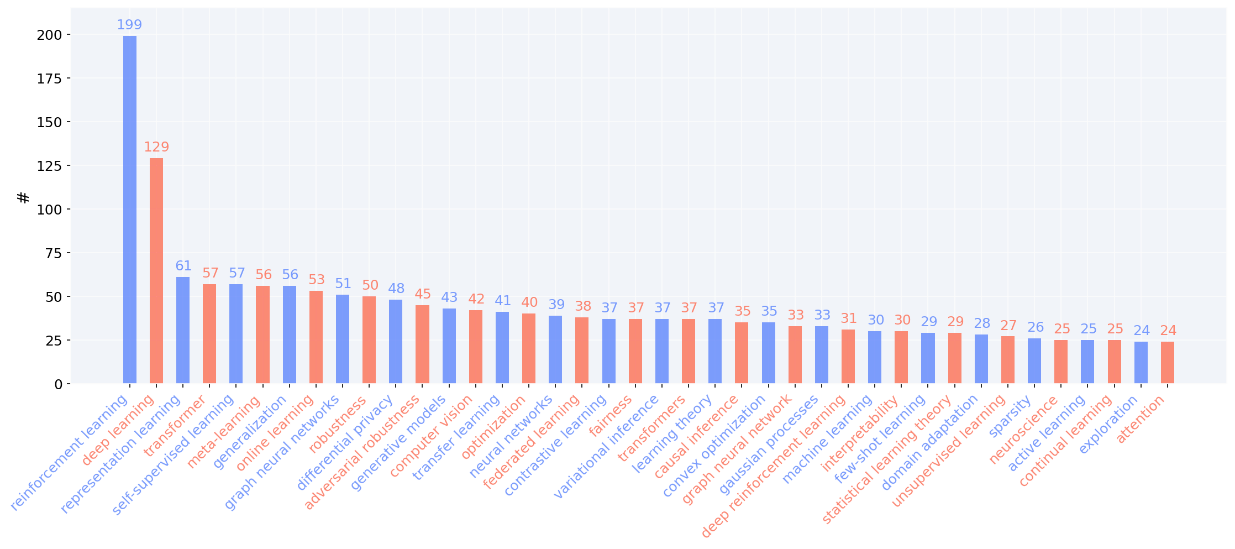 図6:NeurIPS2021投稿論文のキーワード分析 ※2
図6:NeurIPS2021投稿論文のキーワード分析 ※2
次に、NeurIPS 2021の受賞内容について、簡単に説明する。
NeurIPS 2021のOutstanding Paper Awards(6本)に関する論文概要は以下の通りである。
6本のうち、2本が強化学習関連のテーマであり、ここでも強化学習が非常に注目されていることが分かる。
※上記2本は” On the Expressivity of Markov Reward”と”Deep Reinforcement Learning at the Edge of the Statistical Precipice”である。
<A Universal Law of Robustness via Isoperimetry>
【研究機関】
マイクロソフト社、スタンフォード大学
【参考URL】
https://openreview.net/forum?id=z71OSKqTFh7
【発表概要】
古典的な方法論では、n個の連立方程式を解けるようにする為には、一般的にn個の未知数が必要とされている。
一方、深層学習の方法論では、訓練データをスムーズにフィッティングさせるためには、必要な未知数よりもはるかに多くのデータ量を必要とする。
上記の一見矛盾した理由を説明する為に、理論モデルを提案しており、MNISTとImageNetでスケーリング性などを検証している。
<On the Expressivity of Markov Reward>
【研究機関】
DeepMind社、プリンストン大学、ブラウン大学
【参考URL】
https://openreview.net/forum?id=9DlCh34E1bN
【発表概要】
強化学習において、不確実性の下で意思決定する為にはマルコフ過程の報酬関数が非常に重要となるが、その方法論はほとんど解明されていない。
エージェントに実行させたいタスクとして、SOAPs(Set of Acceptable Policies:一連の方策に関する制約事項)、POs(Policy Ordering:方策の優先順位)、TOs(Trajectory Ordering:行動に関する軌道の優先順位)という3つの概念に分解して、報酬関数の表現性を考察出来る。本発表では、それらの概念を用いて考察した結果、マルコフ報酬関数の指定できないタスクがいくつか存在することを例示していた。
そこで、エージェントが3タイプのタスクを最適化できるマルコフ報酬関数を構築、及びそのような報酬関数が存在しない場合に正しく判断する多項式時間アルゴリズムを提案している。
<Deep Reinforcement Learning at the Edge of the Statistical Precipice>
【研究機関】
Google社、モントリオール大学
【参考URL】
https://openreview.net/forum?id=uqv8-U4lKBe
【発表概要】
深層強化学習アルゴリズムに関する既存の比較方法の多くは統計的不確かさを無視しているが、それを解決する為に実行回数を大きくすることは、計算負荷が大きくなり、現実的ではない。
そこで、本発表では、実行回数が少ない場合でも用いることが出来る信頼性の高い指標について、3つのツール「層別ブートストラップ信頼区間」、「performance profile」、「InterQuartile Mean (IQM)」を提案している。
(層別ブートストラップ信頼区間)
単一タスクの平均スコアについて、層別サンプリングによるブートストラップ法で信頼区間を求める。
(performance profile)
実行結果において、ある正規化スコア以上の割合を示す分布を用いる。
(InterQuartile Mean)
分布では、二つの曲線が複数の点で交差するなどの場合、どちらが優位かの判別が難しくなる。そこで、InterQuartile Mean (IQM)を利用する。
<MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers>
【研究機関】
ワシントン大学、アレン人工知能研究所、スタンフォード大学
【参考URL】
https://openreview.net/forum?id=Tqx7nJp7PR
【発表概要】
オープンエンドなテキスト生成の進歩に必要不可欠である、機械学習モデルの生成テキスト分布Qと人間の生成テキスト分布Pの比較指標に関する発表。評価指標として、MAUVEという手法を提案しており、これはテキストが量子化された埋め込み空間でのKL-divergence(尤度比を対数変換し、期待値を取った値)を用いた比較手法となっている。
本提案手法では、タイプIエラー(人間が生成しないテキストをモデルが生成するエラー、Qが大きくPが小さいエラー)とタイプIIエラー(人間がよく生成するテキストをモデルがテキスト生成しないエラー、Qが小さくPが大きいエラー)の両方を考察に入れていることが特徴の一つとなっている。具体的には、KL-divergenceが発散する場合も考慮して、線形結合して指数関数変換して面積を算出している。また、適当な言語モデルを用いて、サンプルから埋め込みベクトルをクラスタリングして近似している。
MAUVEは効率的に計算出来、かつ人間の評価と相関が高く、言語モデルの生成テキストに関する評価をより正しく行える。その上、クラスタリング手法や言語モデルに依存しないことも例示していた。
<Continuized Accelerations of Deterministic and Stochastic Gradient Descents, and of Gossip Algorithms>
【研究機関】
PSL大学、スイス連邦工科大学ローザンヌ校、グルノーブル・アルプ大学、MSR-Inria joint center
【参考URL】
https://openreview.net/forum?id=bGfDnD7xo-v
【概要】
2つの別々のベクトル変数が連続時間で同時に変化するNesterovの加速勾配法の連続版に関する発表。本提案手法は、ランダムな時間の勾配ステップで2つの反復循環する系列に対して、常微分方程式の解析解を利用して計算している。
本手法のメリットは三点あり、一点目がNesterovの加速勾配法と同様の収束率となる点、二点目が他の連続時間モデル手法と比較して理解しやすい点、三点目が連続時間プロセスの離散化による追加誤差を削減している点が挙げられる。
<Moser Flow: Divergence-based Generative Modeling on Manifolds>
【研究機関】
ワイツマン科学研究所、Meta(Facebook)社、UCLA
【参考URL】
https://openreview.net/forum?id=qGvMv3undNJ
【概要】
Moser(1965)による結果を活用して、リーマン多様体上の連続正規化フロー(CNF)を訓練するための方法(MF:Moser Flow)に関する発表。
MFは、他のCNF手法とは異なり、学習時に密度推定器のダイバージェンスを明示的に組み込んでいる。これにより、一般的なバックプロパゲーションに要するODEソルバーの実行を回避している。
本提案手法を用いた結果、従来のCNFと比較して、トレーニング時間が短縮され、テストパフォーマンスが優れており、曲率が一定でない陰関数曲面の密度をモデル化できることが示されている。
また、Datasets & Benchmarks Best Paper Awards(データセットとベンチマークに関する賞、NeurIPS2021から新しく設立)では、”Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research”(UCLAとGoogle社が発表、ベンチマークに使用するデータセットに関する考察)と” ATOM3D: Tasks on Molecules in Three Dimensions”(スタンフォード大学とシカゴ大学が発表、分子間相互作用や分子構造を分析する為の分子3Dモデルに関する考察)が受賞していた。
投稿論文に関する分析や、Awrads内容を見ても、強化学習が非常に重要なテーマとなっていたので、次回のブログではさらに深堀りした強化学習のトレンドについて説明を行う。
※1 https://syncedreview.com/2021/12/01/deepmind-podracer-tpu-based-rl-frameworks-deliver-exceptional-performance-at-low-cost-156/参照
※2 https://guoqiangwei.xyz/neurips2021_stats/neurips2021_submissions.html参照

【執筆者:ITI伊藤 成顕 プロフィール】
大手製造業にて、新設工場の大規模システム構築、IoT構築やAI含む高度なシステム開発などに従事。過去蓄積したノウハウを活用し、DX戦略、DX実現の支援を行うアイ・ティ・イノベーションにて、お客様と共にプロジェクトの成功に奔走している。
