1. はじめに
2022年度(2022年4月~2023年3月)は、国内会議で2022年度 人工知能学会全国大会(JSAI 2022)や電子情報通信学会 パターン認識・メディア理解研究会(PRMU研究会)などに参加した。
そこでは、時系列予測、画像分類、物体検出、画像生成、強化学習、レコメンドシステム、データフリーなシミュレーションモデル等の発表があった。
本記事では、聴講した内容を踏まえ、国内会議のメガトレンドを紹介する。さらに、国際会議の聴講内容と比較しつつ、今後の国内研究動向を予測していく。
2. 聴講した国内会議の研究動向
聴講した分野が多岐に渡り、その全てを本記事で紹介出来ない為、国内会議で聴講した分野を「時系列データをメインに取り扱うAI」、「画像データをメインに取り扱うAI」、「言語データをメインに取り扱うAI」に大きく分類して述べていく。
1) 時系列データをメインに取り扱うAI
RNN・LSTMのモデルをベースとして、「データの種類を増やす」、「前処理に工夫を施す」、「モデルを組み合わせる」などの工夫で精度向上している研究が多かったと感じた。
RNNは、時系列データを学習する再帰構造をもつニューラルネットワークの総称である。しかし、単純なRNNでは「勾配損失」(長い時系列データではネットワークが時系列長に比例して非常に深くなってしまい、情報が上手く伝達されない現象)や「入出力の重み衝突」(時系列データ特有の問題として、現時点で相関が小さくても、将来的には相関が大きくなるような入力もしくは出力があった場合に、重みを大きくすべきものであると同時に、重みを小さくしなくてはいけない、という矛盾が生じてしまう現象)などの問題が発生してしまう。
そこで、LSTMでは、「Input Gate(入力)・Forget Gate(忘却)・Output Gate(出力)」という3つのゲートと、過去の誤差情報を保存することによって、上記の二つの問題に対応している(詳細は割愛)。
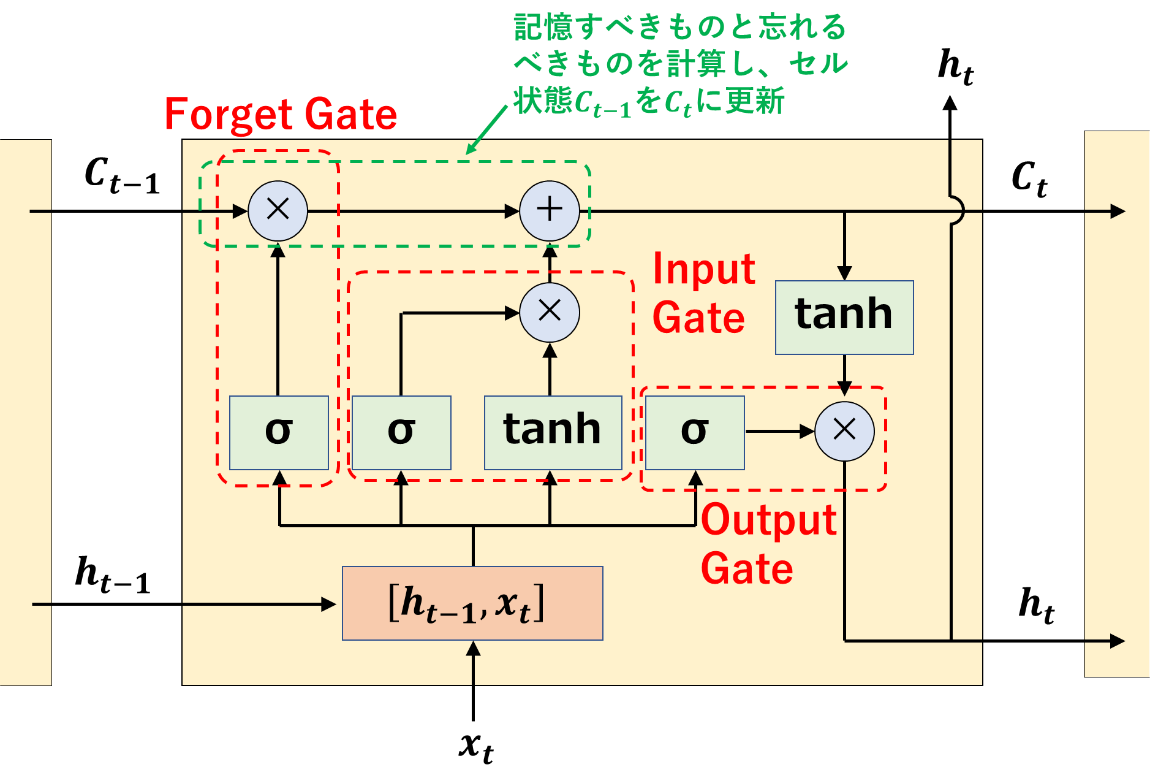
図1:LSTMの構造
例えば、JSAI2022の発表では、RNN・LSTMのモデルをベースにした研究は以下のようなものが挙げられる。
[1F5-GS-10-02] 周波数空間LSTMによる異常呼吸検出
[3E4-GS-2-03] 時系列予測手法の精度比較
[2J4-GS-10-04] リカレント・ニューラルネットワークによるオフィス床需要予測とDiPasquale-Wheaton型オフィス賃料予測
[2D6-GS-2-05] 再帰型ニューラルネットワークを用いた電力需要予測の比較検討
2) 画像データをメインに取り扱うAI
画像生成・画像変換に関する発表と物体検出に関する発表が多かった。画像生成・画像変換の関連研究ではCycleGANやStyleGANなどを発展させた手法、物体検出の関連研究ではYOLOを用いた手法が多かった。以前多く発表されていたようなDCGANやVAEを用いた画像生成やFast R-CNN、SSD等を用いた物体検出は少なくなってきたと感じられる。
CycleGANは、ICCV 2017で発表された論文「Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks」(https://arxiv.org/abs/1703.10593参照)で提案されたGANによる画像変換手法である。CycleGAN以前から存在しているPix2Pixでは、画像変換の入力画像、出力画像に相当する2つの画像の対応関係を学習させる。訓練データとして、2つの画像の輪郭・形状・位置等がぴったりペアになっているものを大量に用意する必要がある為、ペアの画像データを大量に入手出来する事が困難であった。一方で、CycleGANはdomain(分野、領域)の異なる2つの画像データセット同士で学習している。
また、StyleGANは、CVPR 2019で発表された論文「A Style-Based Generator Architecture for Generative Adversarial Networks」(https://arxiv.org/abs/1812.04948参照)で提案されたGANによる画像生成手法である。Mapping networkで潜在変数を潜在空間へ非線形変換し、AdaIN(スタイル変換に関する正規化手法)を用いてMapping networkから得られた潜在空間を解像度ごとにスタイル情報としてSynthesis Networkにマージしている。さらに、低解像度の学習から始め、徐々に高い解像度に対応した層を加えながら学習を進める高解像画像生成アルゴリズム(Progressive Growing)を使用していることも特徴として挙げられる。
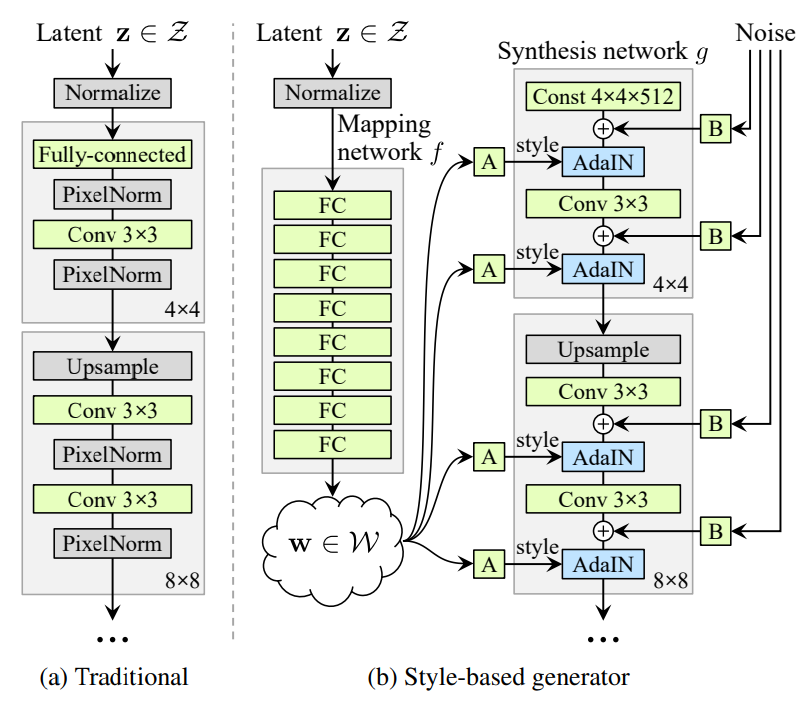
図2:左図(a)がStyleGAN以前の典型的なモデル、右図(b)がStyleGANのモデル
StyleGANの課題として、「droplet」と呼ばれる水滴のようなノイズや、特徴の一部が全体の動きに追随しないというモードが存在していた。最近では、StyleGANを改良し、これらの問題を解消したStyleGAN2(CVPR 2020で発表された論文「Analyzing and Improving the Image Quality of StyleGAN」で提案)やStyleGAN3(NeurIPS 2021で発表された論文「Alias-Free Generative Adversarial Networks」で提案)が存在している。
StyleGAN2では、「droplet」のノイズ対策としてAdaINでない正規化手法の使用やProgressive Growingの代わりに頻出特徴に引っ張られないMSG-GANに類似したネットワークを追加している。また、StyleGAN2の課題として、画像の絶対座標に特徴が固定されてしまうモードが存在していた。したがって、並行移動操作や回転操作に弱いといった弱点がある。
そこで、StyleGAN3では、生成器の入力値を補完フィルタによって離散値から連続値に変換させている。さらに、非線形な活性化関数を用いると一定値になり易い低周波領域情報についても、ローパスフィルタを活用して情報を取り入れられている。

図3:StyleGAN2とStyleGAN3の比較 ※1
なお、日本国内の学会ではStyleGAN2やStyleGAN3を取り入れた発表はほとんど無かった。また、応用研究としては画像のノイズ補正や具体的な画像生成の制御手法(例えばリアルな写真から漫画的な画像への変換等)に関する研究発表が多く見受けられた。例えば、JSAI2022の発表では、上記のGANモデルをベースにした研究は以下のようなものが挙げられる。
[1O1-GS-7-02] CycleGANを用いた宝飾品画像の補正
[1O1-GS-7-04] 環境温度変化に頑健な遠赤外線画像認識にむけた CycleGANを用いたデータ拡張手法の検討
物体検出の手法に関しては、Faster R-CNNやYOLO以前はEnd-to-Endの学習ではなく「物体候補領域タスク」と「物体のクラス分類」の二段階検出が主流であったが、精度・速度を向上させる為、End-to-Endの学習が一般的になってきた。最近の物体検出手法として、YOLOの派生形である「YOLOv7」、「VarifocalNet(VF-Net)」(偽陰性・偽陽性の重要度を考慮して損失関数の交差エントロピーを変形させたモデル)、「DETR」(物体検出手法にTransformerを融合させて画像内の相関を考慮するモデル)などが提案されている。
日本国内の論文で使用されている物体検出モデルは、YOLOの中でも、YOLO v2~YOLO v5のYOLOを活用したモデルが多いと感じている。また、応用研究としては、物体検出を用いたロボット制御などが挙げられる。
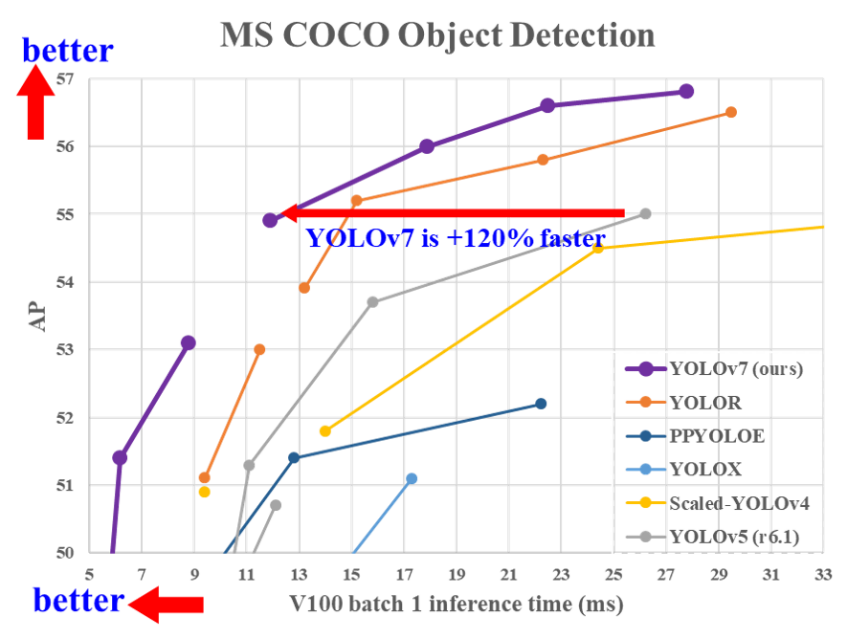
図4:YOLOv7の性能 ※2
3) 言語データをメインに取り扱うAI
言語データをメインに取り扱った研究では、BERTで事前学習されたものをファインチューニングしたものや、OpenAIで公開されているGPT-2、GPT-3をファインチューニングしたものが多かったと感じた。なお、GPT-2とGPT-3では基本モデルは同じであるが、内部構造として表1のような違いがある。
表1:GPT-2とGPT-3の違い
| GPT-2 | GPT-3 | |
|---|---|---|
| Transformerの層数 | 48層 | 96層 |
| パラメータ数 | 15億個 | 1750億個 |
| コンテキストのトークンサイズ | 1024 | 2048 |
| 隠れ層の数 | 1600 | 12288 |
| 学習データ | WebText(40GB) | テキストデータ(45TB) ※前処理後で570GB |
※BERTのTransformer層数は24層、パラメータ数は3.4億個である。
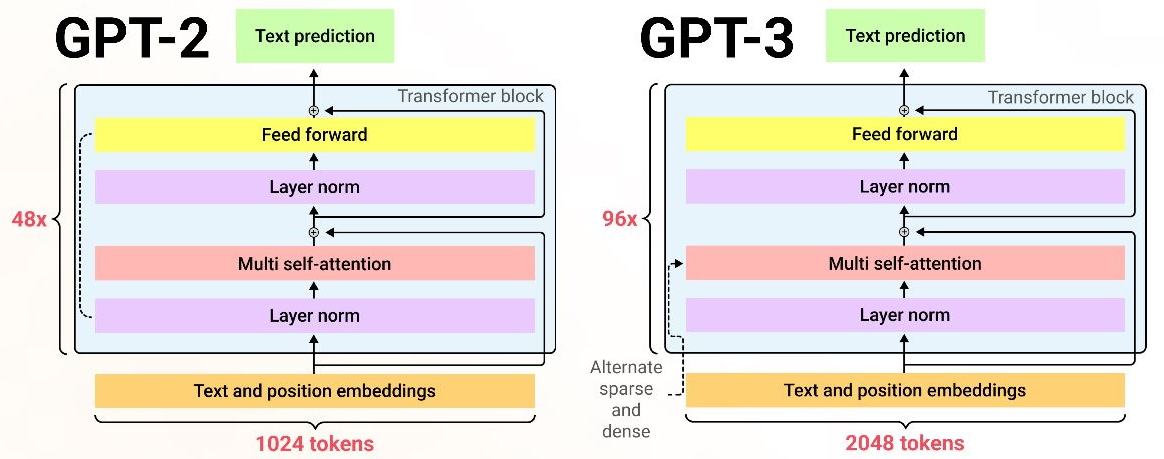
図5:GPT-2とGPT-3のモデル比較
上記に関連した国内研究の一例として、対話応答タスクへの応用やデータ拡張した場合の評価などが挙げられる。
1)~3)で述べたように、一部の国内研究では新しいモデル作成に関する研究も実施されているが、革新的なモデルに関する論文数・発表数は少ないと感じている。新しいモデルの研究よりも、海外で作られた複雑なモデルを用いて、データの追加、前処理・特徴量抽出やデータ分析(クラスタリング等)といった手法で精度向上させていく研究が多いと感じている。
今回のブログでは国内会議を聴講した上での所感に留めたが、次回のブログでは、国際会議ではどのような研究が多いか、さらに国際会議と国内会議を比較して今後の国内研究に関する動向予測を述べていく予定である。
※1 https://medium.com/@steinsfu/stylegan3-clearly-explained-793edbcc8048参照
※2 論文「YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors」を参照

【執筆者:ITI伊藤 成顕 プロフィール】
大手製造業にて、新設工場の大規模システム構築、IoT構築やAI含む高度なシステム開発などに従事。過去蓄積したノウハウを活用し、DX戦略、DX実現の支援を行うアイ・ティ・イノベーションにて、お客様と共にプロジェクトの成功に奔走している。
