2. 個人的に注目度の高いNeurIPS2021の強化学習トピック2選
NeurIPS2021で個人的に注目度の高い強化学習トピック2選(「マルチエージェント強化学習」と「オフライン強化学習」)について、以下で述べるとする。
1)マルチエージェント強化学習
マルチエージェント強化学習(Multi-Agent Reinforcement Learning:MARL)は、複数のエージェントがいる環境にかける強化学習である。複数エージェントでの協調的な学習により、単一エージェントの弱点補強や非同期処理への活用などが行えるようになり、全体として高いパフォーマンスを出せる事が推測されている。具体的な事例としては、交通渋滞の解消、人流、ゲーム理論的な意思決定、スマートグリッドの制御、スポーツ戦略の支援、複数配置の最適化問題(WEBページレイアウトや部屋のレイアウト等)などの分野に役立つと考えられている。
MARLは、協力関係にあるエージェントが複数いる場合、競争関係にあるエージェントが複数いる場合、さらにそれらを組み合わせた場合に分類できる。
MARLの特徴は、集中学習(Centralized learning)と分散実行(Decentralized execution)を考える点にある。一般的な強化学習と同様に、個々のエージェントによる個々の報酬に着目して実行するのが「分散実行」であり、それらのエージェントが協調して全体報酬を最適化する学習が「集中学習」である。
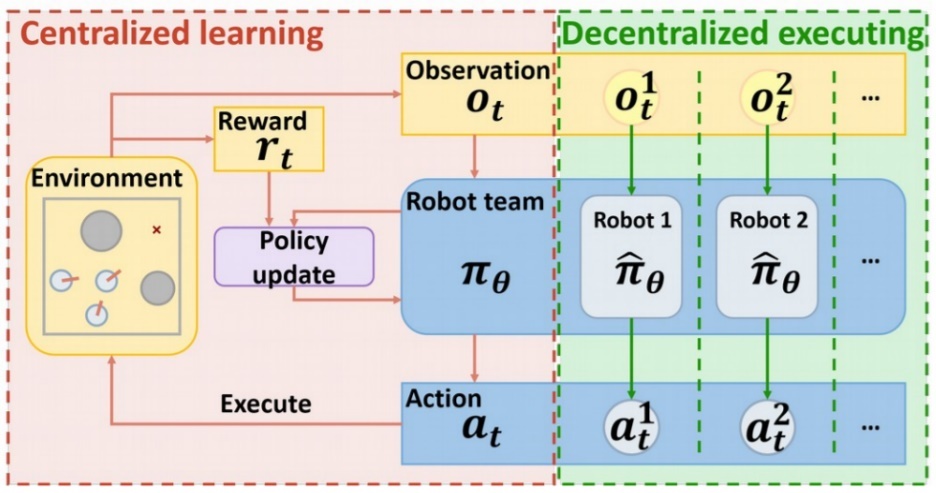
図1:マルチエージェント強化学習の集中学習と分散実行 ※1
MARLでは、以下のような問題が多く取り上げられている。
①:状態空間が大きすぎる為、学習が不十分となる問題
②:複数の利害が発生する為、報酬分配に関する設計が困難である問題
③:MARLを研究する為のシミュレーション環境が少ない問題
これらに取り組むべく具体的なモデルとしては、従来手法の代表的なモデルとしてVDN(Value Decomposition Network)やQMIXなどがある。さらに、最近では、モデル構造にアテンション構造やLSTMモデルを組み込む研究や非同期意思決定の構造を組み込む研究も多くなってきている。
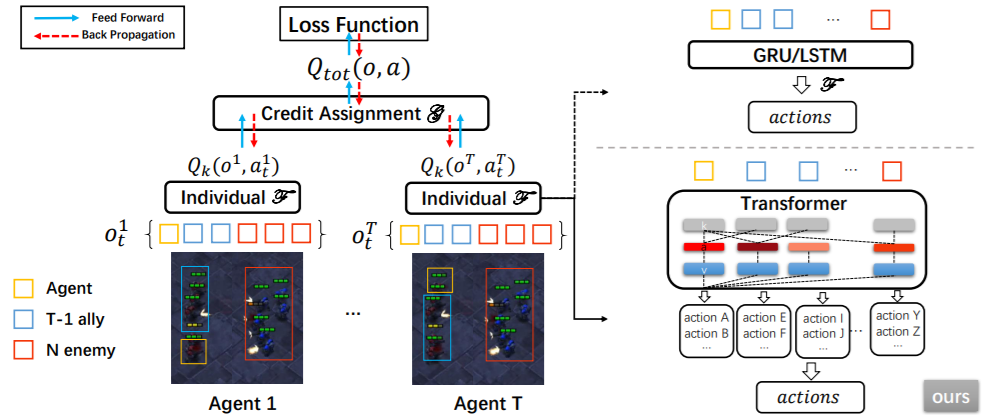
図2:アテンション構造やLSTMモデルを用いたマルチエージェント強化学習 ※2
上記で説明したMARLに関して、NeurIPS2021での発表内容をいくつか抜粋して紹介する。
<Episodic Multi-agent Reinforcement Learning with Curiosity-driven Exploration>
【研究機関】
清華大学、南京大学、NetEase社、アルバータ大学
【参考URL】
https://openreview.net/forum?id=YDGJ5YExiw6
【発表概要】
MARLを用いることで、状態空間が指数関数的に拡大していく問題を解決しようとしている発表。
「EMC」と呼ばれるエピソード型マルチエージェント強化学習を研究している。個々のQ値予測誤差を協調探索の報酬として使用し、Replay Bufferを用いた方策学習を行っている。
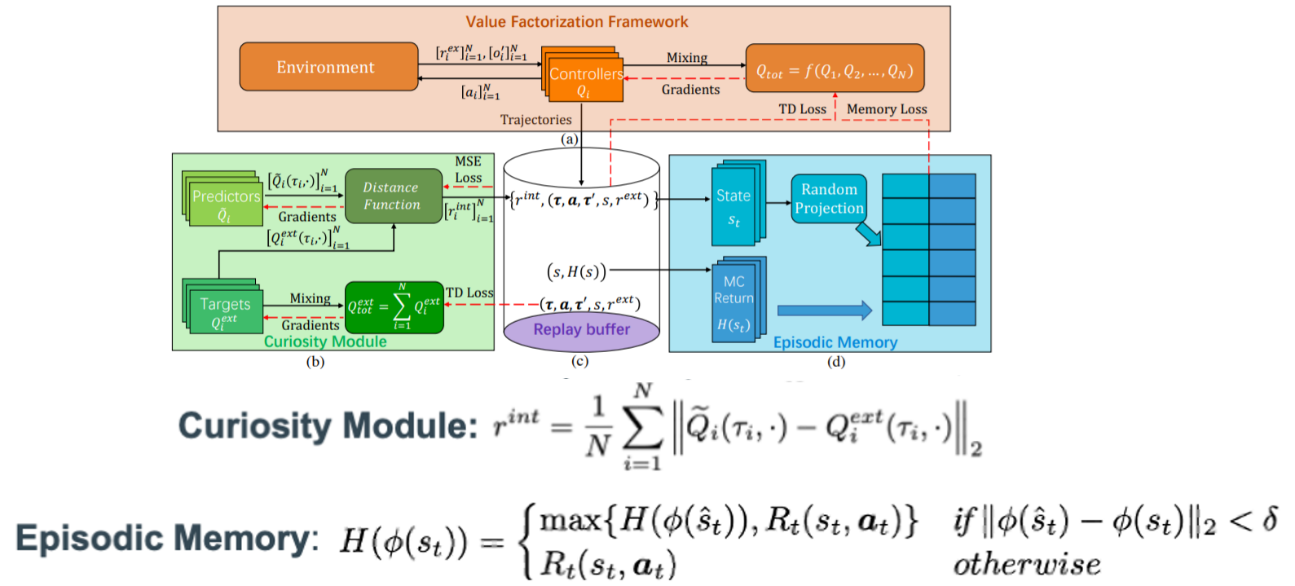
図3:EMCのフレームワーク概要
本発表では、SMAC(StarCraft II Micromanagement)の環境でテストを行っていた。シミュレーション結果として、EMCを用いることで学習が効率的に進み、さらに17タスク中6タスクで好成績を収めている。
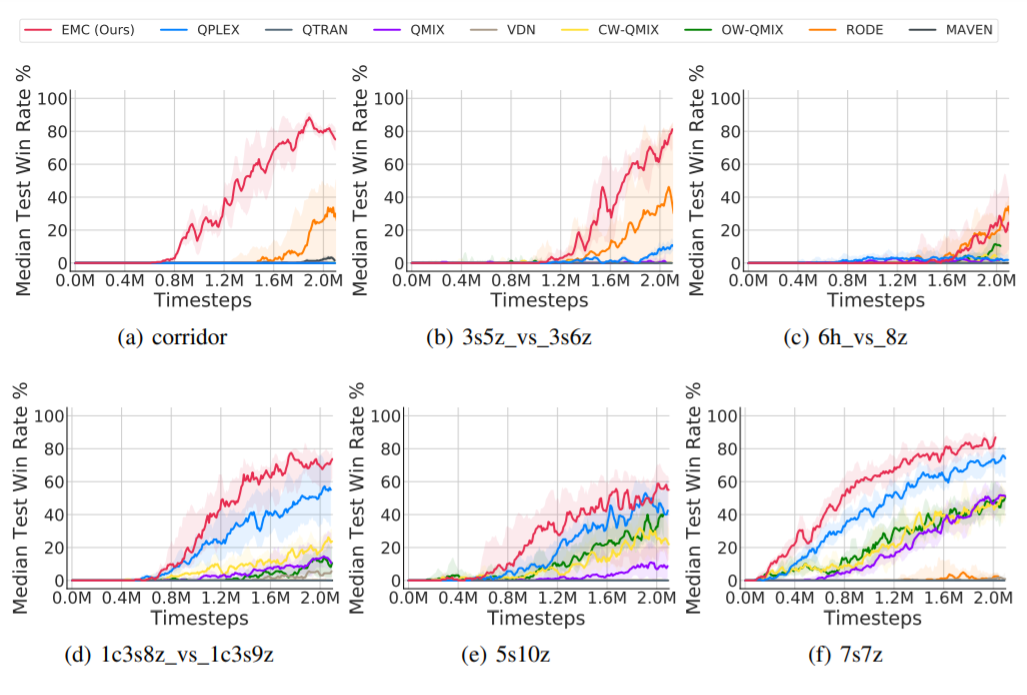
図4:EMCを用いた結果(SMACでの実験)
<FACMAC: Factored Multi-Agent Centralised Policy Gradients>
【研究機関】
オックスフォード大学、リバプール大学、デルフト工科大学、Facebook社
【参考URL】
https://openreview.net/forum?id=wZYWwJvkneF
【発表概要】
COMA(※3)やMADDPG(※4)などの一般的なマルチエージェント型Actor-Criticの手法は、分散型Actorを用いて、中央集権的にCriticを学習させるものである。
(MADDPGは、オフポリシーなActor-criticの一種であるDDPGをマルチエージェント用に変更したモデルである。)
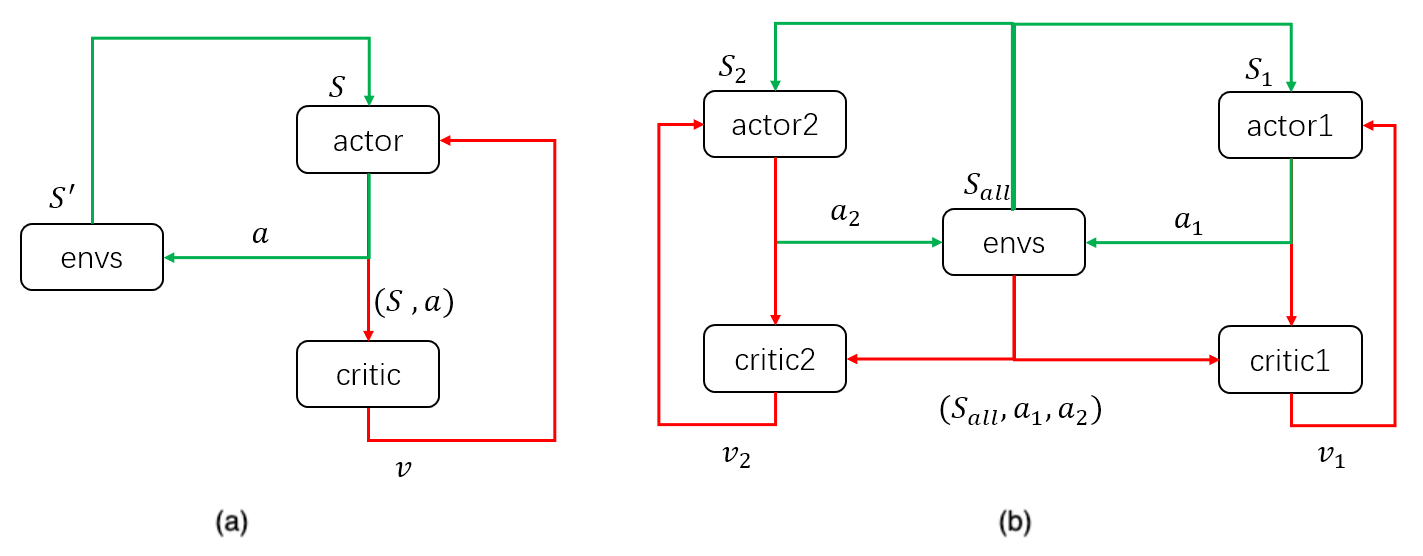
図5:(a)一般的なDDPG、(b)MADDPG(2人のエージェント)
経験的ではあるものの、これらは困難なStarCraft Multi-Agent Chanenge(SMAC)ベンチマークにおいて、QMIXのような価値に基づく方法を著しく下回っている。
そこで、MADDPGとは異なる手法となるFACMACを提案していた。FACMACは各エージェントの行動空間を個別に最適化するのではなく、共同の行動空間全体を最適化する方策勾配推定を行っている。
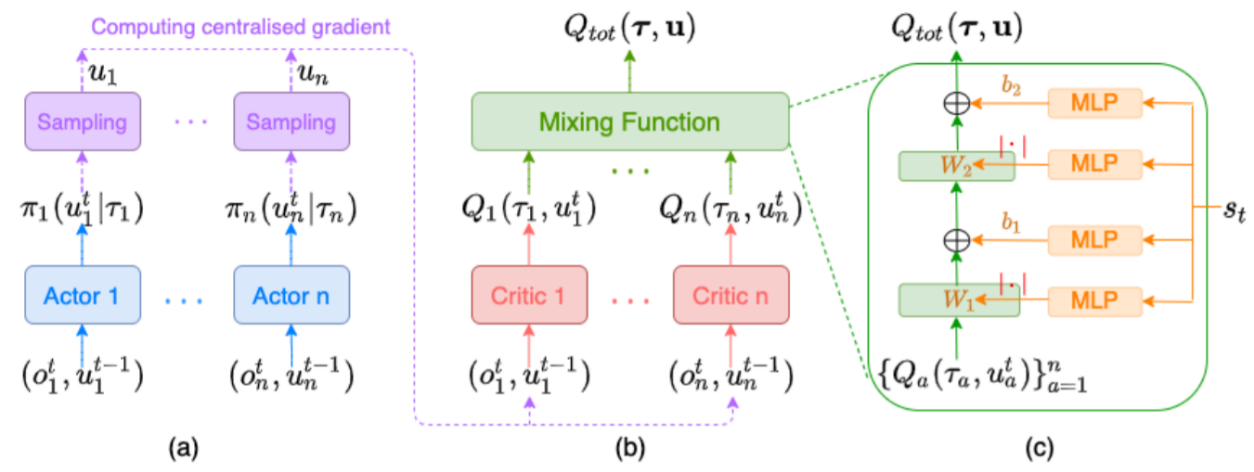
図6:(a)分散型方策ネットワーク、(b)集中学習をするCritic、(c)非線形な混合関数
連続的な行動空間のベンチマークとしてMAMuJoCo、離散的な行動空間のベンチマークとしてSMACで実験を行っていた。マルチエージェント強化学習で良く用いられるMAMuJoCoやSMACで比較した結果、図7の通りになっている。
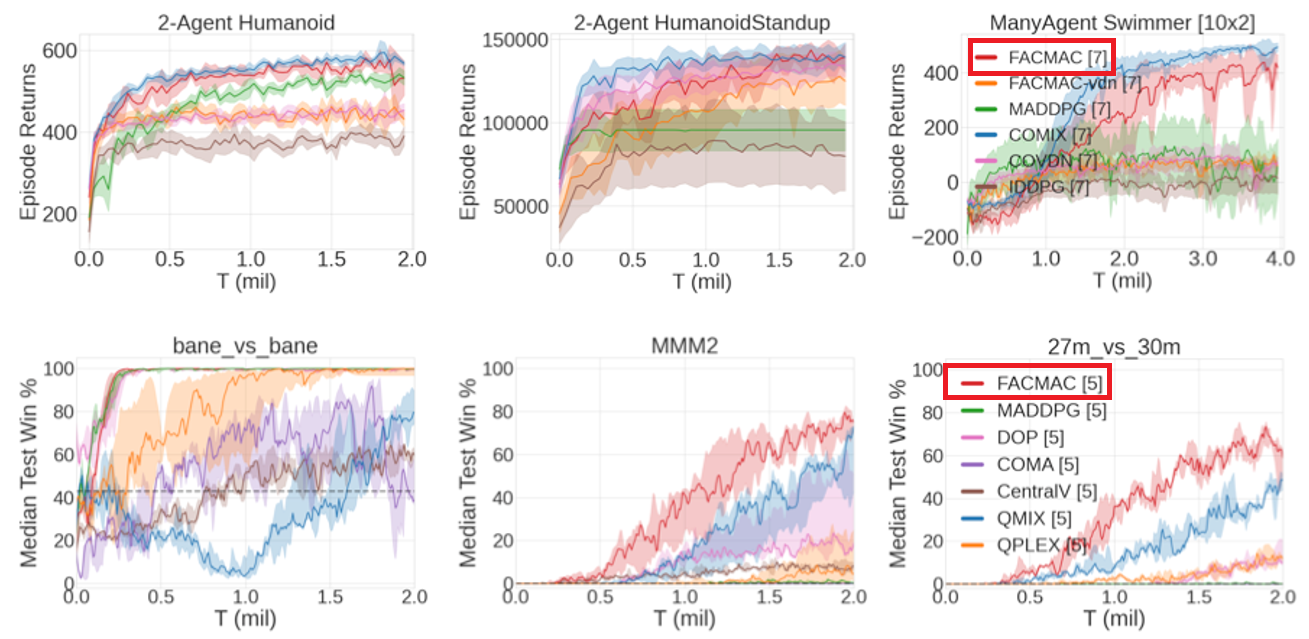
図7:ベンチマークのテスト結果(上段:MAMuJoCo、下段:SMAC)
<Celebrating Diversity in Shared Multi-Agent Reinforcement Learning>
【研究機関】
清華大学
【参考URL】
https://openreview.net/forum?id=CO87OIEOGU8
【発表概要】
近年、深層マルチエージェント強化学習(MARL)を用いて、エージェント間でパラメータを共有することにより、複雑な協調タスクに取り組む研究が多い。しかし、このようにパラメータを共有すると、エージェントは似たような行動をとるようになる傾向がある。一方で、パラメータを共有しない場合では、エージェントはより大きな探索を行う必要があるが、常に異なる振る舞いは必要で無い為、学習コストが余計にかかる。非共有と共有のトレードオフをいかに適応していくかが課題である。
上記を背景として、本発表では、共有型マルチエージェント強化学習において、上記トレードオフに関する研究を行っていた。
個々の効用を表す価値関数Qiを以下のように分解する。
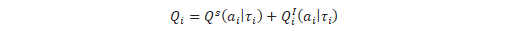
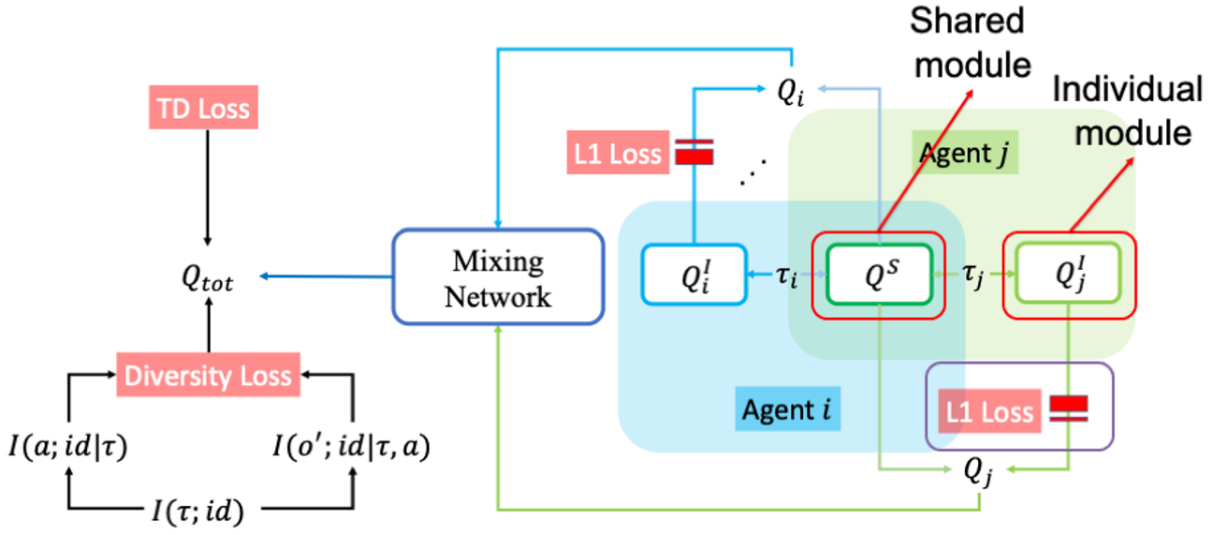
図8:本発表のアプローチ
最適化において、個々の軌道とエージェント間の相互情報量を最大化する情報理論的な最適化関数を使用している。

本発表では、シミュレーション環境Pac-Menを用いている。Pac-Menでは、4人のエージェントが中央の部屋で初期化され、また、周囲の5×5グリッドを観察することが出来る。ドットは、すべての部屋が空になった後にランダムな更新を行う。各部屋の端には3つのドットがランダムに初期化される。
このシミュレーション環境では、異なる部屋への経路は異なる長さを持ち、下:左:上:右=4:8:12:8としている。従って、4つの経路のうち3つはエージェントの観測範囲外であり、探索が困難となっている。エージェントが1つの部屋に集まると、エージェント間で非効率的な競争が発生することになる為、協調的な行動が必要になる。
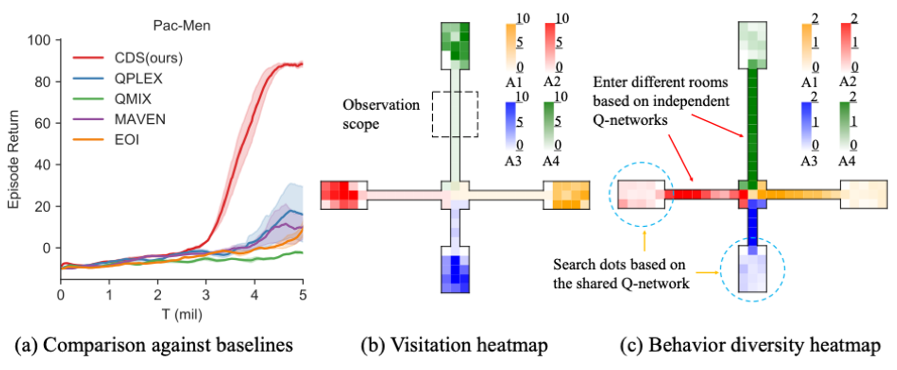
図9:PaC-Menでの実験結果
本提案手法では、他のベースラインとなるQMIXなどと比較して、多様性と共有性の良いバランスを実現していることが分かる。
上記論文のようなモデル以外にも、“PettingZoo: Gym for Multi-Agent Reinforcement Learning”のようなマルチエージェント用のシミュレーション環境に関する発表も有った。
2)オフライン強化学習
一般的なオンライン強化学習では、シミュレーション環境で行動しながら報酬を最大化するように行動価値関数や方策を学習する。一方、オフライン強化学習は過去に収集された状態・報酬・行動のデータセットのみで学習を行う。
オフライン強化学習では、固定されたデータセットとなる為、観測された状態遷移と報酬はデータ収集時の方策に依存してしまう。すなわち、ある方策によって選ばれた行動以外の場合の結果は記録されていないので、上手く探索が出来ず、バイアスのかかった学習となってしまう点がボトルネックとなる。(これを「分布シフト」と呼ぶこともある。)
オフライン強化学習が実用化されると、シミュレーション環境を必要とせずに制御可能となり、当然ながら現実世界とシミュレーション世界の結果差も無くなる。従って、医療関係や自動取引など、幅広い領域で強化学習が適用できるようになる為、応用面を期待して、ここ最近盛んに研究されている。
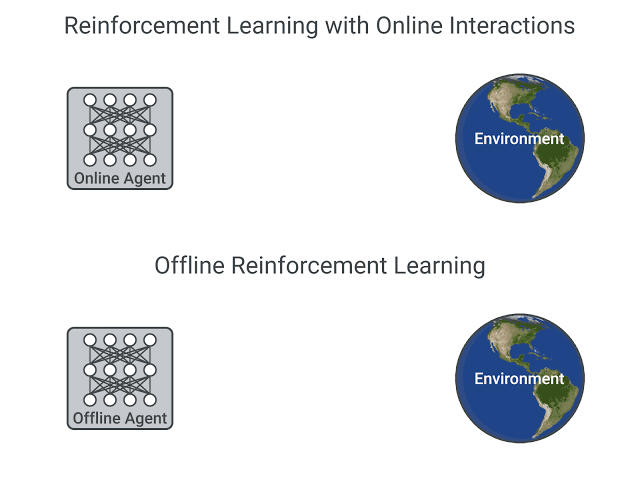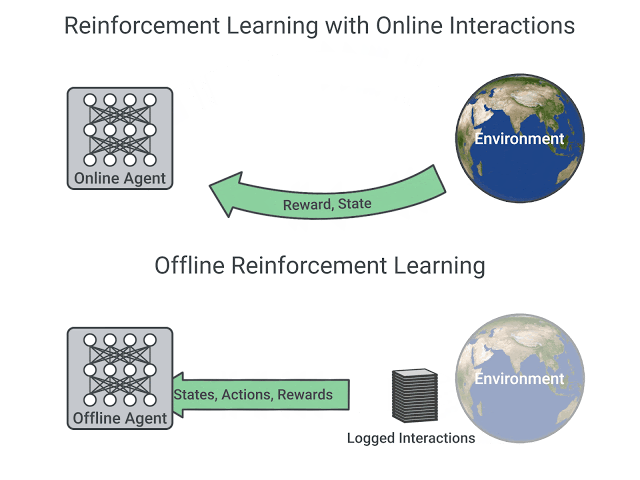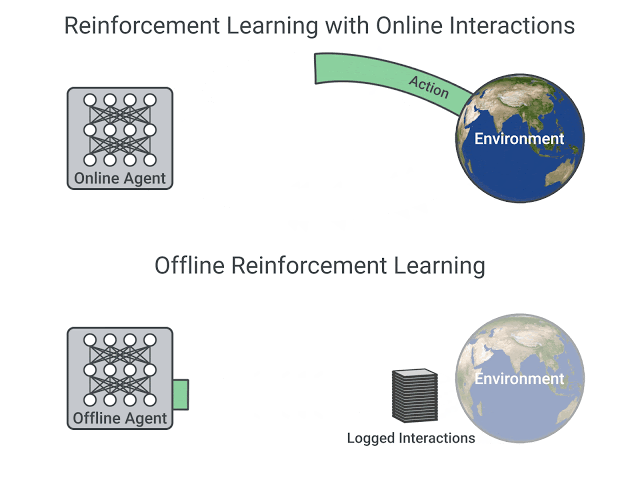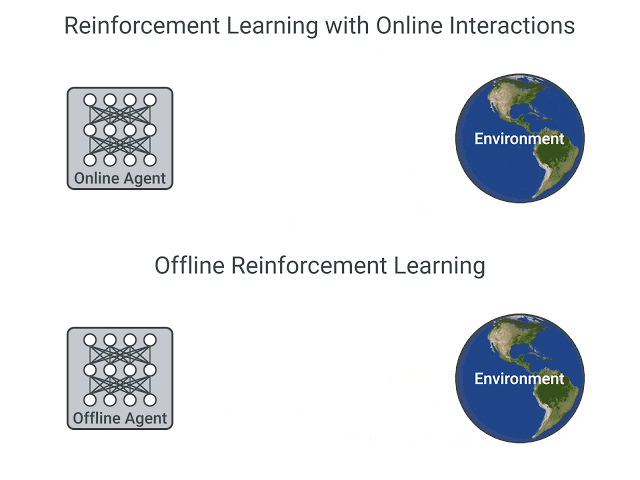
図10:オフライン強化学習の概念図 ※5
分布シフトにより、方策の適切な学習や新しい方策の学習が中々上手くいかないことを述べたが、Conservative Q-Learning(CQL※6)によって、一定の研究成果を上げている。学習に関して、一般的なTD誤差最小化だけでなく、データの無い不確実性の高い部分で過大評価を抑制しつつ、本来価値の高いところを過小評価しすぎてしまうことを回避するように価値を更新している。
さらに、CQLのような分布を用いた研究だけでなく、従来からの模倣学習(IL)の発展形などの研究も数多くあった。
上記のようなオフライン強化学習について、NeurIPS2021での発表内容をいくつか抜粋して紹介する。
<Offline Meta Reinforcement Learning – Identifiability Challenges and Effective Data Collection Strategies>
【研究機関】
イスラエル工科大学
【参考URL】
https://openreview.net/forum?id=IBdEfhLveS
【発表概要】
ベイズ最適な探索を用いたオフラインメタ強化学習(OMRL)に関する発表。最近研究されているVariBAD RL(Zintgraf et al., ICLR’20)でのアプローチを基に、適応的な推定に基づいて探索戦略を計画するように学習するオフポリシーBRL手法を研究していた。
適応的な推定とは、RNN構造を用いて十分な時系列データから信念を表す部分を抽出し、抽出した特徴量と状態空間を合わせたものから方策勾配法で行動を決めている。
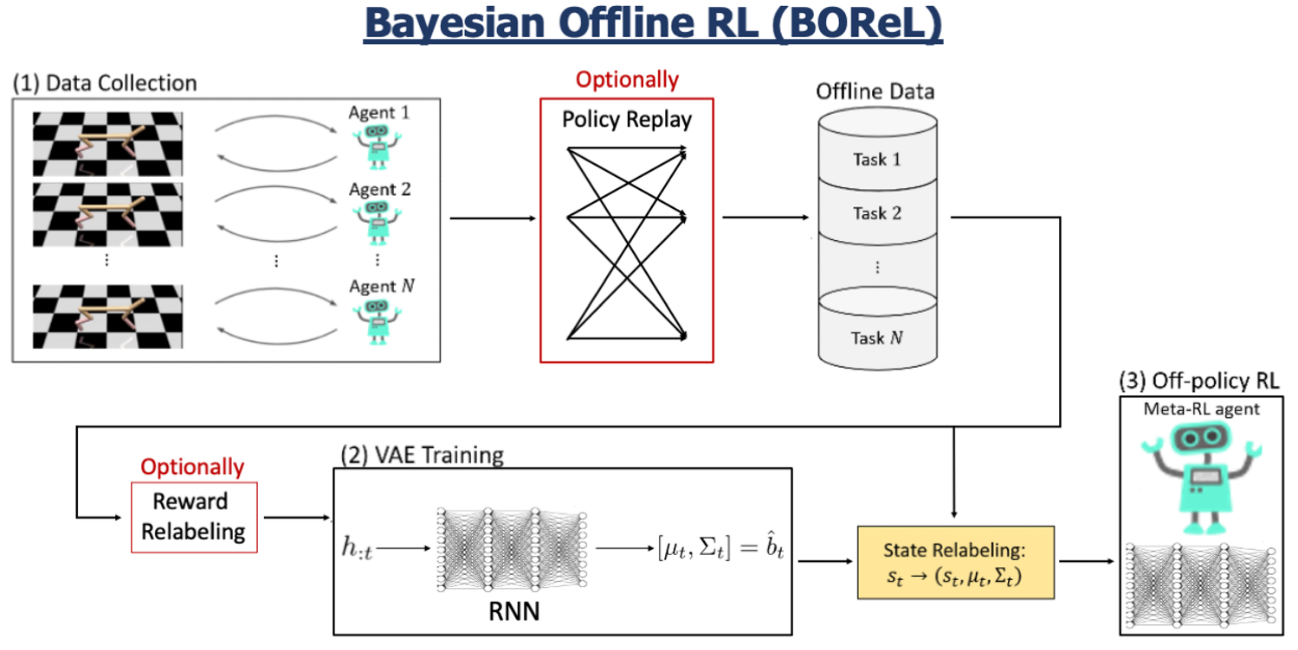
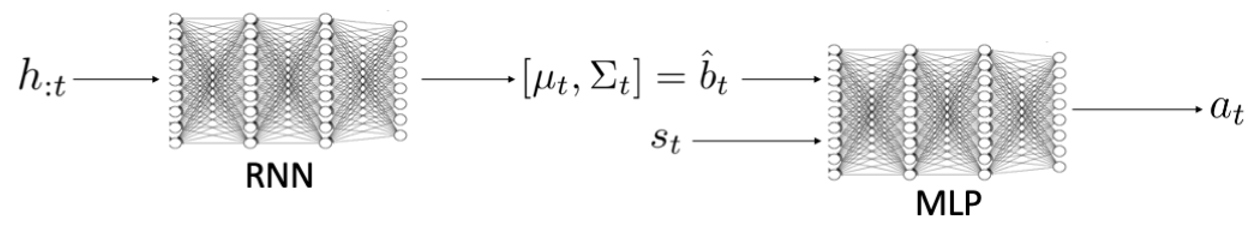
図11:BORelの構造図
R/R(Reward Relabeling)を使用した場合と使用しなかった場合で結果を比較したところ、R/Rを用いたBOReLの結果が優れていた。
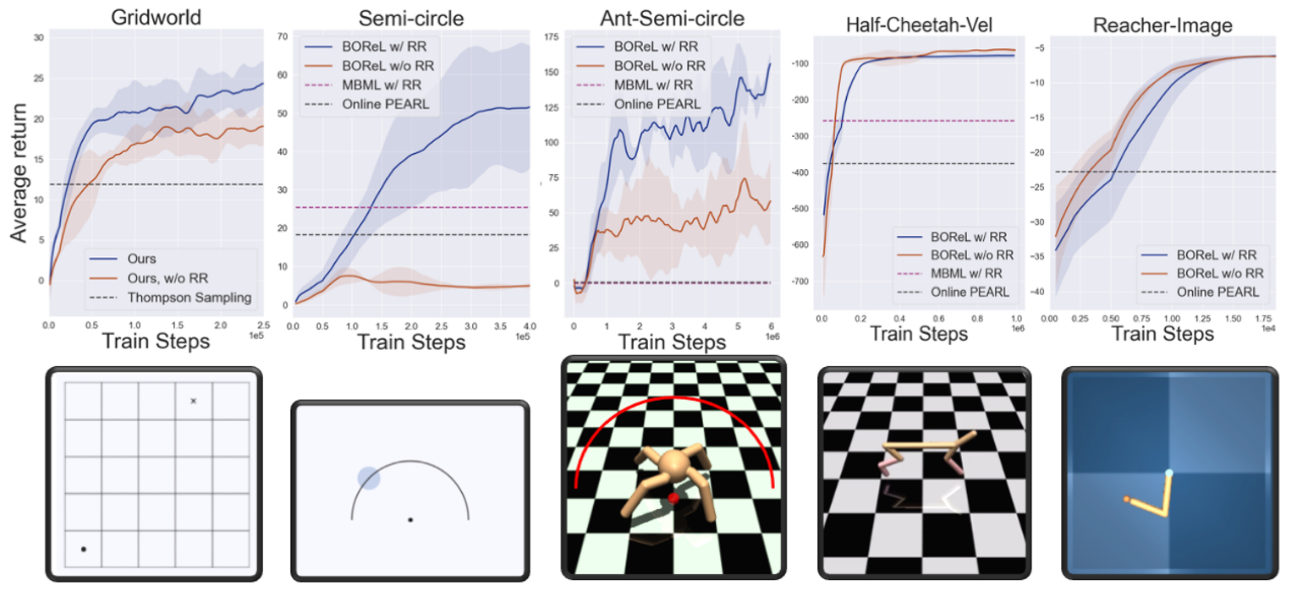
図12:BORelのシミュレーション結果
<Curriculum Offline Imitating Learning>
【研究機関】
上海交通大学、マイクロソフト社
【参考URL】
https://openreview.net/forum?id=q6Kknb68dQf
【発表概要】
一般的な強化学習はオンライン環境が必要であるのに対して、模倣学習(IL)ではオフラインで学習が可能となる。
一方で、経験的にILは方策能力に限界があり、収集されたデータセットから平凡な行動を学習してしまう傾向がある。
「BC」(Behavioral Cloning)は人間の行動を模倣できていたら報酬を与えるILの一種であり、本発表ではBCを用いたカリキュラム学習に関する発表を行っていた。
BCでは、初期分布に関するギャップ、サンプル数と状態空間の複雑さから発生するデータセットと環境に関するギャップ、学習誤差に関するギャップの三つを考えている。
一般的なオフライン強化学習と異なり、次のような方策の下で、オフラインデータセットから模倣するターゲットとなるカリキュラムの段階を選択している。
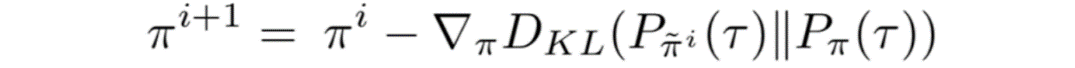
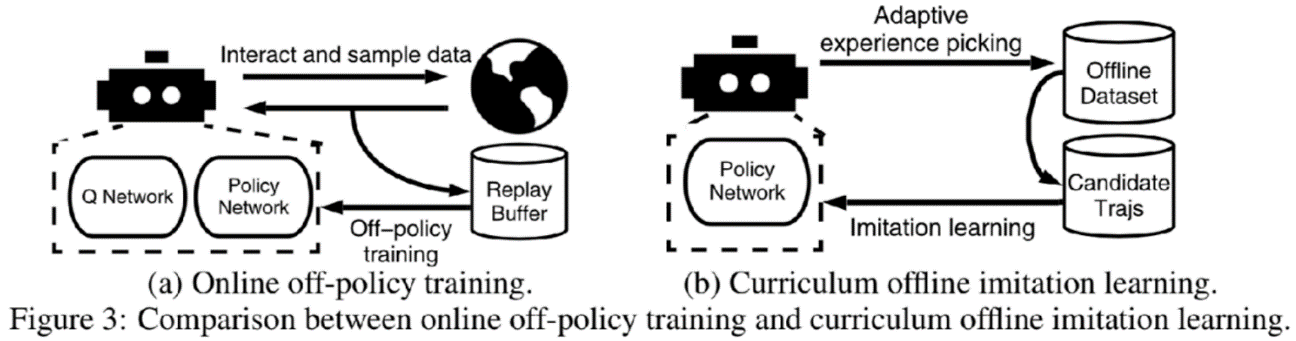
図13:オンラインオフポリシー強化学習とカリキュラムオフライン模倣学習
さらに、移動平均を用いてフィルタリングなどを行い、各カリキュラムで値を更新する際、無駄な軌道を削除している。
シミュレーションを行った結果、いくつかの環境で本提案の手法(COIL)は、良いパフォーマンスを出している事が分かる。
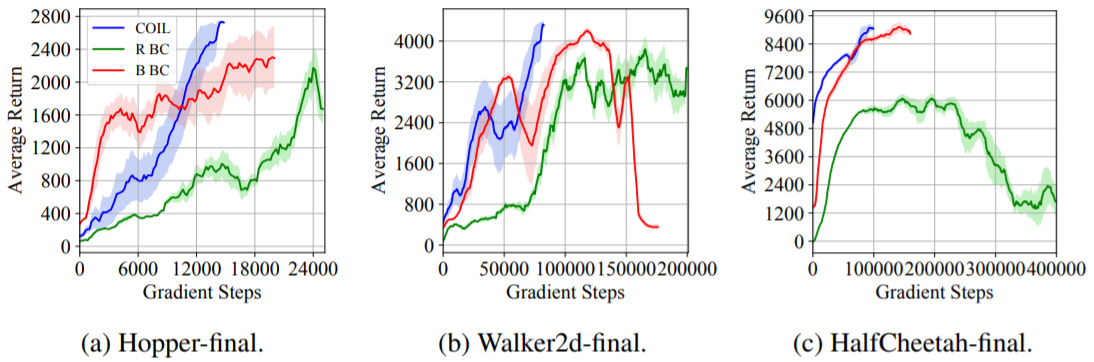
図14:COILのシミュレーション結果
<Conservative Offline Distributional Reinforcement Learning>
【研究機関】
ペンシルベニア大学
【参考URL】
https://openreview.net/forum?id=Z2vksUFuVst
【発表概要】
オンライン強化学習は、一般的にリスクとコストが高い。そこで、オフライン強化学習を用いてリスク(VaR系)を考慮した方策を学習する研究発表をしていた。
本提案手法をCODAC(Conservative Offline Distributional Actor-Critic)と呼んでおり、以下のような特徴がある。
・保守的なリターン分布推定に基づくオフライン分布型RLアルゴリズムである。
・大きな方策目標群(期待収益など)を視野に入れてる。
・リスクセンシティブおよびリスクセンシティブで最新のパフォーマンス
Out-Of-Ditribution(=OOD)はデータの無い領域である為、価値関数や期待報酬の予測で不確実性が高く、エラーの確率が大きい領域となる。
そこで、CODACではOODを考慮し、分布外での行動に関して、リターンの予測分位数にペナルティを課すことにより、オフラインとして適応させている。
本発表では、CODACをランダムな初期状態から緑色の円に、可能な限り早く移動することを目標とした「Ant robot」を用いて実験していた。
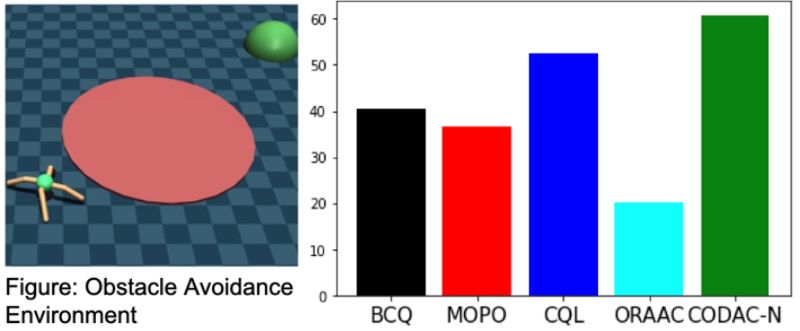
図15:CODACのシミュレーション環境(左図)とシミュレーション結果(右図)
3. NeurIPS2021で投稿された強化学習の発表に対する所感
NeurIPS2021では、非常に強化学習のトピックが多く、その中でも応用先が多岐に渡る「マルチエージェント強化学習」と「オフライン強化学習」に特化して、今回紹介した。
マルチエージェント強化学習の研究動向としては、汎用的なフレームワークや汎用性の高いモデルが分かっていない為、価値関数の共有方法などを変えて様々なモデルを研究していたものが多かった。さらに、計算負荷を低くする研究やシミュレーション環境開発などの要素がまだ発展途上の段階ではないかと考えられる。
また、オフライン強化学習では、模倣学習の応用研究だけでなく、データセットの分布を考慮した学習の研究も多数あった。
これらから分かる通り、5年前のような「ゲームAIで強化学習モデルをひたすら改良・改善していくフェーズ」から「データドリブンやマルチエージェントなどの強化学習適用の現実解に近い研究のフェーズ」に移行した印象を受けている。
今後、これらの研究が出来れば、それに伴い、データモデルやシステムアーキテクチャなどの変更も余儀なくされる為、このような研究動向を知った上で如何に拡張性を取れるようにしておくかが非常に重要ではないかと感じた。
※1 Juntong Lin, Xuyun Yang, Peiwei Zheng and Hui Cheng. “End-to-end Decentralized Multi-robot Navigation in Unknown Complex Environments via Deep Reinforcement Learning” arXiv preprint arXiv:1907.01713, 2019.
※2 Siyi Hu, Fengda Zhu, Xiaojun Chang and Xiaodan Liang. “UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers” arXiv preprint arXiv:2101.08001, 2021.
※3 Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli and Shimon Whiteson. “Counterfactual multi-agent policy gradients. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
※4 Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. “Multiagent actor-critic for mixed cooperative-competitive environments.” In Advances in Neural Information Processing Systems, pages 6379–6390, 2017.
※5 https://offline-rl.github.io/より引用
※6 Aviral Kumar, Aurick Zhou, George Tucker and Sergey Levine. “Conservative Q-Learning for Offline Reinforcement Learning”. ICML2020.

【執筆者:ITI伊藤 成顕 プロフィール】
大手製造業にて、新設工場の大規模システム構築、IoT構築やAI含む高度なシステム開発などに従事。過去蓄積したノウハウを活用し、DX戦略、DX実現の支援を行うアイ・ティ・イノベーションにて、お客様と共にプロジェクトの成功に奔走している。
